Google Research has introduced TurboQuant, a memory compression algorithm designed to shrink the working memory of large AI models during inference with minimal impact on accuracy. The announcement immediately sparked a wave of “Pied Piper” jokes online, a nod to HBO’s Silicon Valley and its mythical near-lossless compression. The comparison is cheeky, but the core idea resonates: squeeze far more out of limited memory, without degrading what matters.
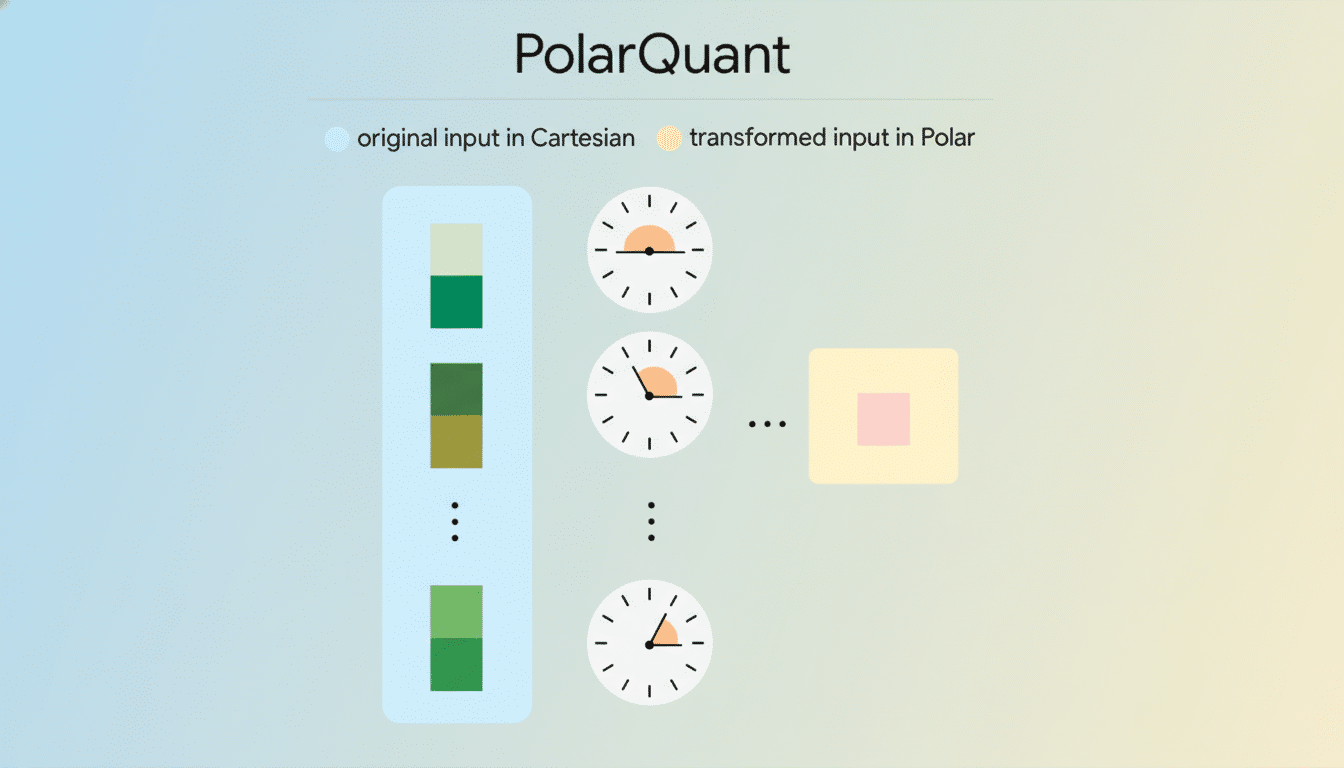
According to Google’s researchers, TurboQuant uses a form of vector quantization to compress the key–value (KV) cache that powers a model’s attention mechanism. Early results claim at least 6x reductions in cache size while maintaining model quality. The team plans to present the work at the ICLR 2026 conference, detailing two enabling techniques: a quantization scheme dubbed PolarQuant and a training-and-optimization method referred to as QJL.
Why TurboQuant Matters for AI Inference Memory
Inference, not training, is where many organizations now feel the heat. The KV cache grows with sequence length and batch size and can dominate GPU memory at longer contexts, forcing trade-offs between throughput, latency, and quality. As model providers push 128K or even million-token contexts, the memory bill balloons. Compressing that cache without materially hurting outputs is the type of efficiency win that reverberates across infrastructure costs and user experience.
Industry engineering notes from projects like vLLM and NVIDIA’s TensorRT-LLM consistently highlight the KV cache as a primary bottleneck for serving large language models. In practical deployments, it often constrains batch size and multi-tenant packing, which directly drives cost per token. If TurboQuant’s 6x figure holds under real workloads, operators could pack more sessions on the same hardware, extend context windows, or both.
Under the Hood of TurboQuant’s KV cache compression
Google characterizes TurboQuant as vector quantization tailored to the peculiarities of attention caches, where precision errors can ripple through generations. PolarQuant and QJL are the two pillars: the former focuses on how vectors are discretized into compact representations; the latter steers training and optimization so models remain stable and accurate under aggressive compression. While implementation specifics will arrive with the paper, the directional takeaway is clear—compression is fused tightly with model behavior, not bolted on as a naive afterthought.
That focus on end-to-end impact mirrors a broader pattern in AI systems work. Techniques like FlashAttention showed that rethinking memory movement, not just math, unlocks disproportionate speedups. TurboQuant extends that mindset to the persistent memory footprint of attention, setting the stage for complementary gains when paired with efficient kernels and scheduler-aware serving stacks.
The Pied Piper Meme And The Reality Check
Social media quickly branded TurboQuant the real-life Pied Piper, with jokes about Weissman scores flying. The cultural shorthand works because both stories revolve around “extreme compression without visible loss.” But there’s an important distinction: TurboQuant targets a very specific substrate—the KV cache of transformer models—rather than generic files or media. It’s surgical, not universal.
And for now, it’s a research breakthrough, not a product drop. Results come from lab evaluations, and the researchers haven’t rolled this out widely. That matters: production serving is messy, with irregular batch sizes, diverse prompts, custom attention variants, and strict SLOs. Sustaining quality while wringing out 6x memory across that variability is the next test.
What It Could Unlock for AI inference at scale
If validated in the wild, TurboQuant could cut per-token costs and power usage by enabling denser packing of sessions on the same GPUs and by lowering memory traffic, one of the dominant energy sinks. For edge deployments, compressing KV caches might make higher-quality models feasible on smaller accelerators. For cloud providers, it creates headroom for longer contexts and larger batch sizes, directly improving throughput.
The enthusiasm isn’t confined to researchers. Cloudflare CEO Matthew Prince framed TurboQuant as a potential “DeepSeek moment” for Google, alluding to the way DeepSeek challenged assumptions on efficiency and hardware requirements. Whether that comparison sticks depends on reproducibility and how quickly serving frameworks like vLLM, OpenAI’s Triton-based stacks, or NVIDIA’s TensorRT-LLM can integrate similar compression paths.
Limits and open questions for TurboQuant adoption
TurboQuant addresses inference memory, not training. That means the massive RAM footprints of pretraining and fine-tuning remain unsolved here. There are also questions about robustness across architectures: mixture-of-experts, speculative decoding, retrieval-augmented generation, and custom attention mechanisms may interact differently with compressed caches.
Accuracy measurement will be scrutinized. Average-case benchmarks like MMLU or MT-Bench can mask tail degradations that matter to enterprise users. Expect calls for standardized long-context and safety evaluations under compression, with per-task tolerances spelled out. Instrumentation from organizations such as Stanford’s CRFM and LM Evaluation Harness maintainers could help establish apples-to-apples comparisons.
What to watch next as TurboQuant heads to ICLR 2026
The ICLR presentation should answer the big questions: how PolarQuant and QJL trade off speed versus compression, how accuracy is preserved at 6x, and how portable the method is across model sizes. Eyes will also be on whether Google releases reference implementations and whether external teams can replicate the results on open models like Llama 3 or Mistral within popular serving stacks.
The Pied Piper memes may fade, but the underlying demand won’t. Memory is the tax on modern AI. If TurboQuant reliably cuts that bill without noticeable quality loss, it will become one of the year’s most consequential infrastructure advances—less flashy than a new model, but exactly the kind of systems work that changes the economics of AI at scale.