Google has introduced an AI compression technique designed to curb one of the industry’s biggest power drains—memory movement—in large language model inference. The research effort, known as TurboQuant, targets the memory-hungry parts of AI systems and promises to shrink their footprint by up to 6x, a change that could translate directly into lower data center energy use.
While GPUs grab the headlines, it’s the constant shuttling of data to and from memory that often dominates electricity consumption during inference. By compressing what models store and retrieve most frequently, Google’s approach aims to cut the joules per token generated, squeezing more useful work out of existing infrastructure.
How Google’s AI Compression Works Inside Transformers
TurboQuant focuses on two notorious energy and latency hotspots in modern transformers: the key–value cache (the short-term memory that grows with conversation length) and vector search structures (used for retrieval and matching). The system applies mathematically rigorous transformations—such as randomized rotations—and quantization to make these data structures far smaller while preserving the relationships models rely on.
Think of it as a specialized, loss-aware zip for the AI runtime. Instead of compressing the model’s static weights—which many teams already do with 8-bit or 4-bit quantization—TurboQuant compresses the dynamic data created during generation and retrieval. That means fewer bytes pulled from high-bandwidth memory or DRAM, less time idling on memory waits, and lower total energy use per request.
The promise is straightforward: with up to 6x smaller caches and indexes, servers spend less power moving data and can pack more concurrent requests onto the same silicon. For long prompts and extended chats—where the cache balloons with every token—those savings can compound.
Why Memory Traffic Drives Power Bills in AI Inference
Semiconductor research has long shown that moving data is frequently more energy-intensive than computing on it. Stanford’s Mark Horowitz and others have documented that fetching from off-chip memory can cost orders of magnitude more energy than a floating-point operation. Google’s own TPU studies point to memory bandwidth as a hard limit for throughput and efficiency in large models.
That is why compression aimed at the runtime, rather than only the model weights, matters for sustainability. By reducing memory traffic during inference, data centers cut the dominant share of energy per response. Multiply that across billions of daily tokens and the grid impact becomes material.
The International Energy Agency estimates global data centers consumed roughly 460 TWh in 2022 and warns demand could rise sharply by 2026 without aggressive efficiency gains. Techniques that trim energy per token—like TurboQuant—are among the fastest levers operators can pull while grid expansions and new capacity lag.
Implications For Data Centers And The Grid
Compression that lightens memory loads gives cloud providers immediate headroom. With smaller caches, the same GPU racks can serve more concurrent sessions or longer contexts before spilling memory, reducing the need to spin up additional nodes. That not only cuts electricity draw but also eases cooling, a nontrivial slice of facility power that operators track via PUE.
The ripple effects reach the supply chain. If inference becomes more tokens-per-watt efficient, hyperscalers can stretch existing fleets of NVIDIA and AMD accelerators further, easing near-term pressure on scarce power and permitting. It complements other software-side advances—quantization, sparsity, mixture-of-experts routing—that collectively shift the industry from brute-force scaling to smarter utilization.
There is precedent for software efficiency moving the sustainability needle. Google’s use of AI for data center cooling previously delivered up to a 40% reduction in cooling energy. TurboQuant aims for a parallel win inside the AI stack itself, targeting the pieces of inference that burn watts every time a user types another token.
What To Watch Next For AI Compression And Efficiency
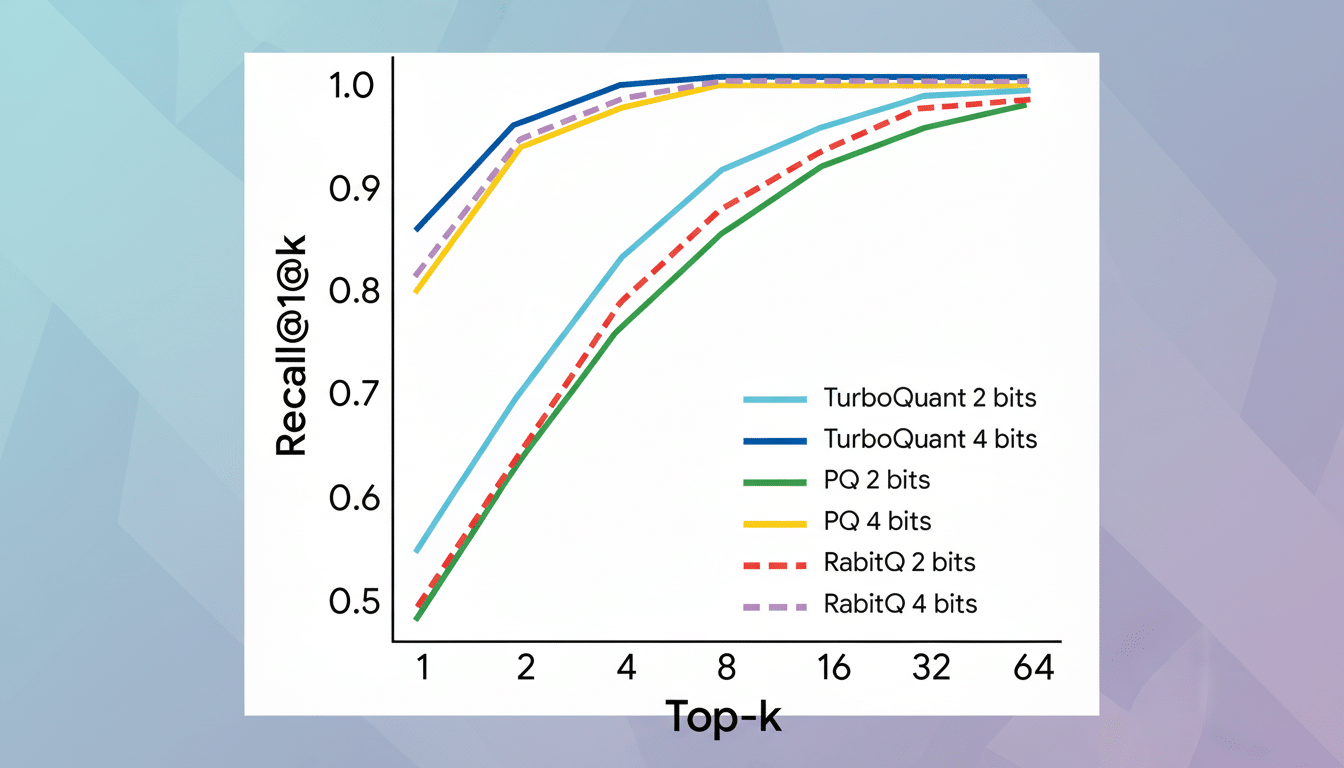
Key questions now are practical: How quickly will TurboQuant integrate into mainstream frameworks, and how does it perform across diverse model sizes and workloads? Independent validation via benchmarks such as MLPerf Inference will help quantify energy-per-token gains and any accuracy trade-offs in real deployments.
If the approach scales, the benefits won’t be limited to hyperscale data centers. Leaner caches and retrieval structures could make advanced assistants run affordably on smaller edge servers and, in time, on-device for premium smartphones and laptops—pushing intelligence closer to users while throttling back data center energy demand.
The broader takeaway is unmistakable: with smarter compression at the heart of inference, AI progress doesn’t have to ride solely on ever-larger server farms. By shrinking what matters most—the data we move, not just the models we build—Google’s new technique points to a more efficient path for scaling AI.
