ChatPlaygroundAI is making a bid to simplify AI decision-making with a steep 89% discount on lifetime access to its comparison workspace, a tool that lets you run a single prompt across 20+ models and inspect results side by side. For anyone tired of juggling tabs and guesswork, the pitch is straightforward: faster prompt iteration, clearer trade-offs, and more accurate outputs in less time.
Why Side By Side Drives More Accurate AI Results
No single model is best at everything. Benchmarks from organizations like Stanford’s Center for Research on Foundation Models (HELM) and the community-run LMSYS Chatbot Arena routinely show that model rankings shuffle depending on task and domain. A system that excels at coding might not be the most reliable for legal summarization or data extraction, and the “best” answer often hinges on constraints like length, tone, or citation needs.

Comparative prompting shrinks that uncertainty. Instead of trusting one reply, you can inspect multiple candidates at once, score them against a rubric (factuality, clarity, source fidelity, style), and pick the winner—or fuse elements from two. Teams that treat this like A/B testing for language find they converge on stronger prompts and more dependable outputs. It’s the same logic behind ensemble methods in machine learning, now made practical for daily workflows.
What ChatPlaygroundAI Brings To The Workflow
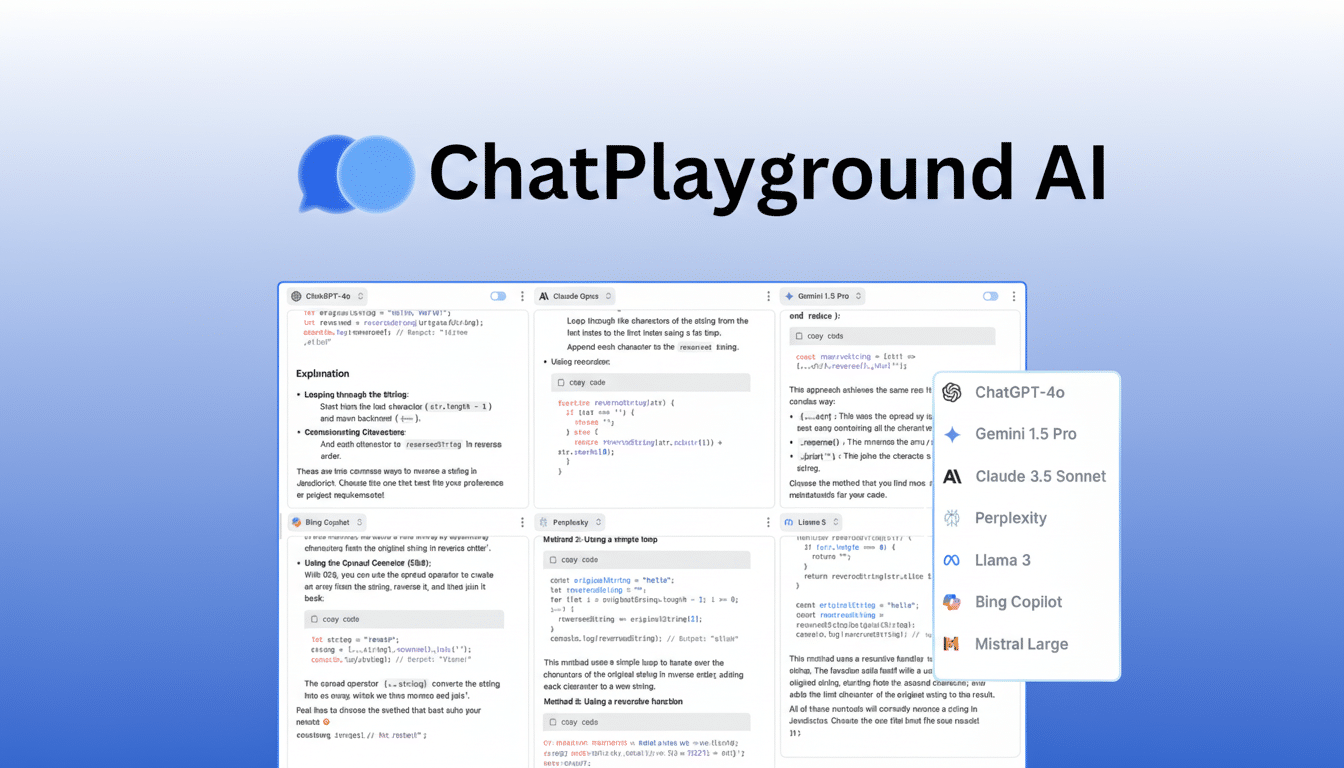
The platform’s core feature is a multi-model runner that sends a single prompt to leading systems—including families like GPT, Claude, and Gemini—and displays results in a clean, comparable grid. From there, you can tweak prompts, rerun, and watch differences surface instantly instead of hopping between apps.
Beyond head-to-head comparisons, it bundles practical tooling: prompt templates and variables for fast iteration, saved conversations to preserve context, AI image generation for creative briefs, and multimodal chats that can analyze PDFs and images. Unlimited messages and ongoing updates position it for heavy use, whether you’re prototyping code assistants or standardizing content guidelines.
Real Examples Where Side By Side Pays Off
Developers can pit code fixes from several models against unit tests, then lock in the most reliable chain-of-thought style for future prompts. Product managers can upload a requirements PDF, ask for a risk summary, and compare which model best preserves nuance and terminology. Marketers can generate five landing-page variants in parallel, then blend the highest-converting headline from one model with the clearest CTA from another to ship faster with fewer revisions.
This approach also sharpens governance. If your team catalogs “golden prompts” alongside winning outputs, you’re building a lightweight evaluation harness. That aligns with guidance in the NIST AI Risk Management Framework: define criteria, test consistently, and document why outputs meet the bar. Side-by-side visibility makes that discipline easier to practice, not just prescribe.
How To Judge AI Model Winners Objectively
To get the most from comparisons, set a simple scoring sheet before you start:
- Accuracy: Are key facts correct and verifiable?
- Completeness: Did it cover all requested points and edge cases?
- Structure: Is the answer skimmable and aligned to your format?
- Constraints: Does it follow tone, length, and citation rules?
- Latency/Cost: Is speed or token efficiency a factor for production?
Run the same prompt across models, rate quickly, then iterate. Small prompt adjustments—explicit instructions, domain examples, or tighter output schemas—often flip the leaderboard. Over time you’ll learn which models dominate specific tasks and can route requests accordingly.
Pricing Details And What The 89% Off Includes
The current offer drops the lifetime plan to $67.15 from a listed $619 when using a promo code at checkout, reflecting an 89% cut. The plan advertises unlimited messages, access to 20+ models in a single interface, prompt engineering utilities, chat with PDFs and images, built-in image generation, saved threads, and ongoing feature updates. It’s a one-time purchase aimed at professionals who would otherwise juggle multiple subscriptions—or settle for one model and hope for the best.
Bottom Line: A Faster Way To Compare AI Models
Accuracy in AI isn’t just about using a stronger model; it’s about choosing the right model for the task and shaping the right prompt. ChatPlaygroundAI’s side-by-side workflow turns that into a repeatable process, trimming trial-and-error and lifting confidence in what you ship. With the 89% discount on lifetime access, it’s an appealing way to operationalize AI comparisons without the tab chaos.
