Microsoft has put a staged recovery in place after a major Azure outage disrupted cloud services and consumer apps globally. While the company says it has rolled back to the last known good configuration and is re-routing traffic to healthy nodes, it says customers should expect intermittent failures while it restores capacity and rebalances traffic to the global edge.
Microsoft explains likely cause and containment steps
Microsoft said the initial view is that an unexpected service-level configuration change in Azure Front Door, the company’s global application acceleration and web application firewall service, triggered the issue. As a containment measure, changes to related and affiliated services remain temporarily blocked to avoid a blanket failure as the rollback to a known good state continues. This extends to customer configuration changes as a precautionary measure when responding to large-scale incidents.
The platform team is entering an incremental, ring-based restoration configuration—rehabilitating nodes, draining unhealthy endpoints, priming hungry caches, and intensively adjusting load-balancing to avoid collapse.
Extent of impact and which customers were affected
Since Azure Front Door operates at the edge, the incident didn’t just affect a single data center or part. Even if compute in a region stayed healthy, requests presented by a degraded edge could fail or time out. User-reported outage trackers such as Downdetector recorded spikes in numerous markets as sites and APIs became unreachable.
The pain was on display for both enterprises and consumers. Microsoft 365 sign-ins and the Azure Portal were flaky, and some tenants saw their identity flows via Microsoft’s Entra ID slow or fail. Alaska Airlines reported disruptions to “critical systems.” In the UK, Vodafone’s telecom customers and Heathrow Airport operations were hit; consumer-facing services like Xbox Live and Minecraft experienced availability issues when ID and edge routing were impaired.
What recovery means for customers right now and next
微软内部的客户服务,”Ryan 加雷尔:“最重要的是:从下一代广告平台到与 HCD 市场的新管理关系,再到我为之投资的某些研究团体,都简单地表明了其他联盟使我们的内部竞争率在很大程度上一直在过去几年中快要失败。不幸的是,直到我们获得这所大学,该广告牌开始恶化,才证明诚实是可能的。”
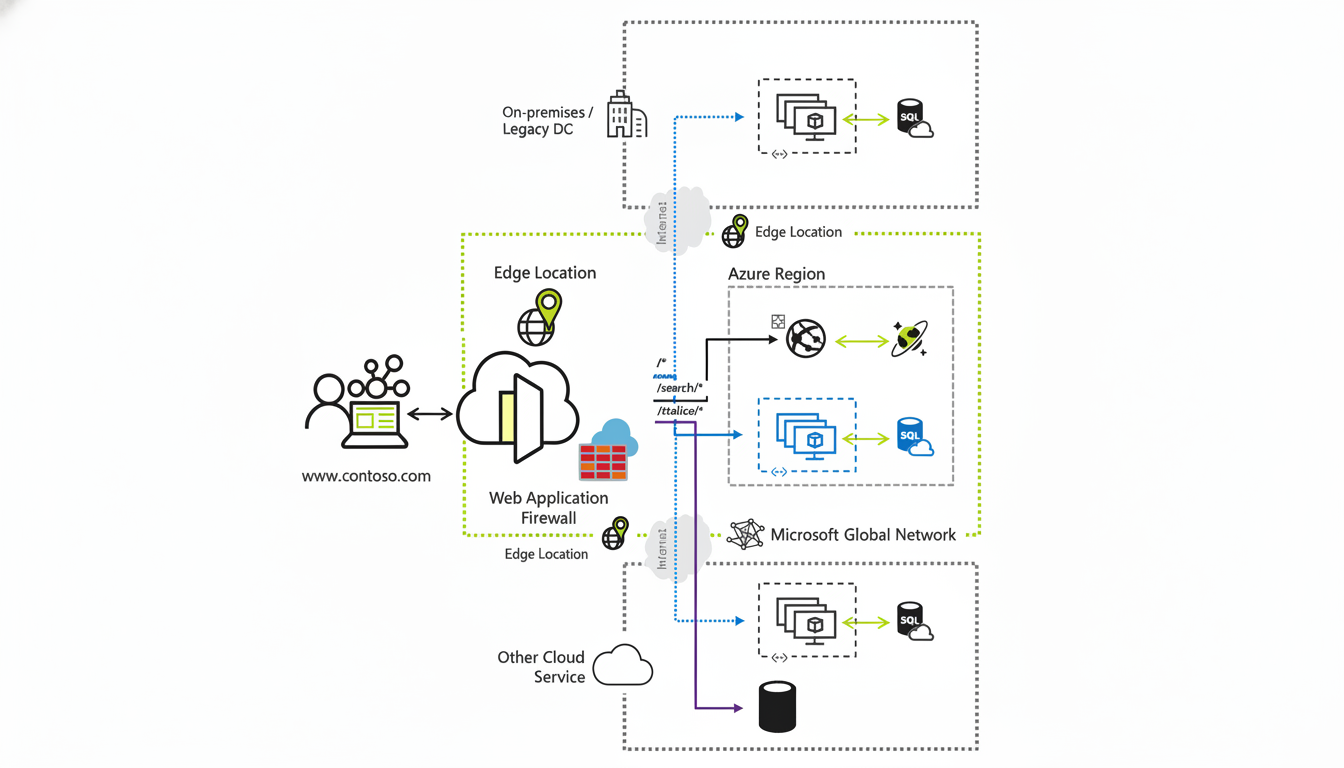
Expect a bumpy return to normal. As traffic is rebalanced and safe nodes are identified, many requests will continue hitting unhealthy nodes. The global rollback is ongoing, and Microsoft has advised customers not to make configuration changes or deployments outside the global safe rollout until it is completed. For teams with mature failover plans, temporarily redirecting traffic outside Azure Front Door—leveraging Azure Traffic Manager or direct DNS steering to origin—can provide partial service recovery, but reimaging is non-trivial and may introduce security and capacity risks if not rehearsed.
Action checklist during the global rollback
- Avoid making configuration changes or deployments until the rollback completes.
- Expect intermittent failures as traffic is rebalanced and capacity is restored.
- If you have mature failover plans, temporarily route outside Azure Front Door using Azure Traffic Manager or direct DNS steering to origin.
- Recognize that reimaging is non-trivial and may introduce security and capacity risks if not rehearsed.
- Monitor Azure Service Health for updates and the preliminary root cause analysis.
Why concentration risk keeps biting critical services
Incidents like this highlight how a few hyperscale platforms have become sole points of logical failure for the internet. Outage research conducted by the Uptime Institute has shown that a larger proportion of major disruptions now exceed $100,000 in direct costs, with reputational damage exacerbating losses. Authorities concerned with operational resilience, like the FCA in the UK and DORA in the EU, urge enterprises to prepare for provider-wide disturbances.
Architecturally, the implication is to lower correlated dependencies. Active-active designs across multiple Azure regions, fail-open designs appropriate for non-sensitive reads, break-glass paths for identity, and out-of-band runbooks for DNS and traffic management can all help limit downtime. Multi-cloud is not the solution; however, removing the edge and identity planes from a single vendor may reduce the blast radius for mission-critical customer journeys.
Microsoft typically releases a preliminary root cause analysis through Azure Service Health following stabilization, accompanied by a detailed post-incident review. Easier guardrails on configuration pipelines, smaller canary rings for global edge services, automated rollback triggers, and segmentation of control planes to address potential future failures seem likely to come next. Azure’s infrastructure accounts for about a quarter of global cloud spending, implying that when disruptions occur, they affect all industries. Credits under service-level agreements may help ease the financial burden, but the emphasis currently is on steady recovery and credible, actual change to avoid a repeat of the global edge misfire. For cloud leaders, the current major outage is a clear signal to verify failover expectations today—before the next event tests them in production again.