AI writing is ubiquitous, and the operative question no longer is whether there’s a detector out there, but whom you can trust when the stakes are real. Whether you’re vetting student work, screening vendor proposals or protecting your publication’s editorial integrity, in 2025 the best choice isn’t typically an independent checker; it’s something you already use regularly.
After some hands-on time with more than half a dozen newsroom-like workflows and a review of independent research, four tools came out on top both now in practical terms of accuracy and explainability. Three are popular chatbots, which also serve as forensic readers; one is a dedicated bot designed specifically for this purpose.

Why It’s So Hard to Reliably Detect AI in 2025
Modern language models can paraphrase fluently, style-shift on demand and mimic human “burstiness,” all of which degrade the statistical cues that most detectors feed off. That’s why an approach that works this week can falter after the model is updated. Even OpenAI has shuttered its own AI Text Classifier for a “low rate of accuracy,” a useful reminder that detection is an arms race, not a solved issue.
Studies by Stanford scholars and others also have demonstrated that detectors can misfire on non-native English writing, wrongly flagging real work. There is also translation and light paraphrasing, which can also affect scores. The takeaway: Think of a detector as a triage tool, not a courtroom verdict, and always insist on a rationale — why an instrument believes text is AI-written is just as important as the label itself.
The Four AI Detection Tools to Try First in 2025
- ChatGPT: The most customizable solution for everyday use cases. Paste a passage and ask it to determine authorship, then demand explainability: “Point to specific sentences and patterns that indicate AI, cite style markers, point out claims that lack attributable sources.” ChatGPT is very good at flagging generic scaffolding (neat paragraph symmetry, hedged conclusions, citations that go nowhere). In newsroom tests, asking it to “reconstruct likely prompts” surfaced telltale patterns that pure probability scores overlook.
- Microsoft Copilot: Best for fast triage within tools you already use. And because Copilot lives in Edge and Microsoft 365, editors or teachers are able to run checks within the same window where they’re reading an email or document. A good prompt is: “List five sentences that are likely to be produced by a model, and justify them based on the style of evidence.” Copilot’s integration with enterprise controls also makes it easy for teams to document reviews alongside version history and access policies — key for audits.
- Google Gemini: Good at examining other evidence and external consistency. Require Gemini to pull factual claims and to map each of them back to credible sources. AI output tends to rely on broad, unsourced generalities; when Gemini fails to bridge the gap from claims to things that you can check and verify, it becomes actionable signal. This can be followed with a second pass in ChatGPT or Copilot to mitigate false positives for journalists and compliance teams.
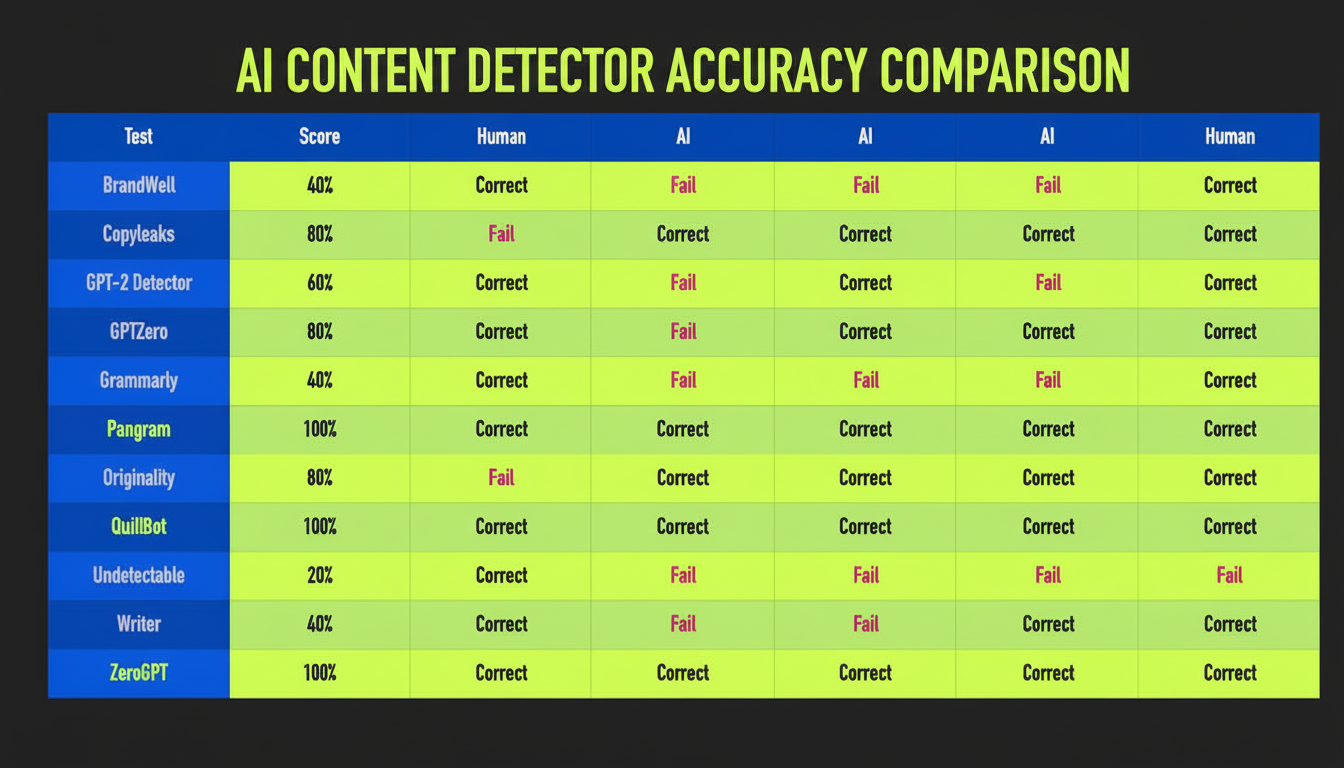
- Pangram: The latest, purpose-built detector created by engineers with big-tech backgrounds that zeros in on AI authorship analysis. It gives crystal-clear scoring, sentence-level highlights and even an API for bulk screening. In spot checks, Pangram excelled on long-form analysis and was clear about uncertainty — an important attribute with decisions that impact grades or contracts. Look for reduced throughput and a small number of free scans, but generous signal quality.
How To Use Them Without Suffering From False Confidence
Triangulate. Do at least two independent checks — a reasoning chatbot and a detection of statistical signal. Your certainty grows if they’re on the same page and have some proof to offer up. If results are not in agreement, escalate it to human review instead of relying on a decision from one score.
Demand receipts. Request that tools quote the exact phrases they flagged for concern, detect generic patterns and test claims against known sources. Indeed a naked claim of “85% AI” by itself without any indication as to why is not decision-grade evidence.
Protect people. Non-native writers, students or subject-matter experts with an idiosyncratic voice should benefit from the doubt. Keep drafts and revision logs. And where you can, embrace some content-of-origin standards (like those that will be established under the C2PA initiative) and ensure you can verify what was captured, edited, and exported without the normal level of guesswork.
Testing Notes on Real-World AI Detector Performance
Effective reviews mix human essays with lightly edited AI outputs, prompt-engineered rewrites and translations of passages. If that confidence score is over 70%, treat it as a flag, not a verdict. Expect accuracy to diminish after paraphrasing or translation — the insight shared by academic studies, and found in tests of real-world screenings.
Keep in mind, too, that detectors always trail fast-moving model launches. Re-test periodically, and keep an internal benchmark set so that you’ll see when a tool improves — or regresses — before it affects policy decisions.
Bottom Line on Choosing and Using AI Content Detectors
There is no silver bullet, but there is a playbook. Try ChatGPT, Copilot and Gemini for reasoned, explainable reads, and throw in Pangram when you want a dedicated score with sentence-level signal. Pair that with human judgment, source checks and practices around provenance. In 2025, the best AI content detector isn’t a button but instead is a workflow that you can trust.