OpenAI takes aim at Google with the release of GPT Image 1.5, a new computer vision model with greater control, cleaner edits, and up to four times faster renders. The model is coming to all ChatGPT users as well as via the company’s API, suggesting OpenAI’s “code red” stance is translating into more rapid product changes and not just far-off roadmaps.
What’s new in GPT Image 1.5 and its precision upgrades
The headline upgrade is precision. GPT Image 1.5 hopes to follow directions without “reinterpreting” a whole frame, one of the most vexing pain points for teams racing to iterate on a lone concept. Request a cooler key light or a less toothy smile and the model is designed to maintain general composition while effecting that specific change.
- What’s new in GPT Image 1.5 and its precision upgrades
- Faster generation and synthetic workstation workflow
- Gemini heat is on as Google’s models pressure OpenAI
- Why iteration quality matters for real production workflows
- More visual responses within ChatGPT for clearer answers
- What to watch next as GPT Image 1.5 expands to all users

OpenAI points out that we also get new controls to help keep a person’s face recognizable, control over lighting, composition, and color tone, as well as all the basic edit controls already present. That mix is important for production work, where a single character or brand motif must be consistent across dozens of iterations. In practical terms, this is an attempt to minimize the drift that so many generators suffer from when considered prompts are relatively low-grain.
Faster generation and synthetic workstation workflow
Speed is the other pillar. OpenAI says generation can be up to 4x faster, which should reduce feedback cycles from minutes to seconds for a lot of use cases. A move that reduces this lag is both a quality-of-life feature that can speed things up overall, and it can increase throughput in creative pipelines where teams will sometimes test dozens of variants before settling on a final cut.
In better service to that workflow, ChatGPT now has a dedicated Images entry point on the sidebar that acts less like a chat thread and more like a creative studio. OpenAI applications lead Fidji Simo shows off new viewing and editing screens, as well as inspiration taken from trend prompts and preset filters to spark ideas.
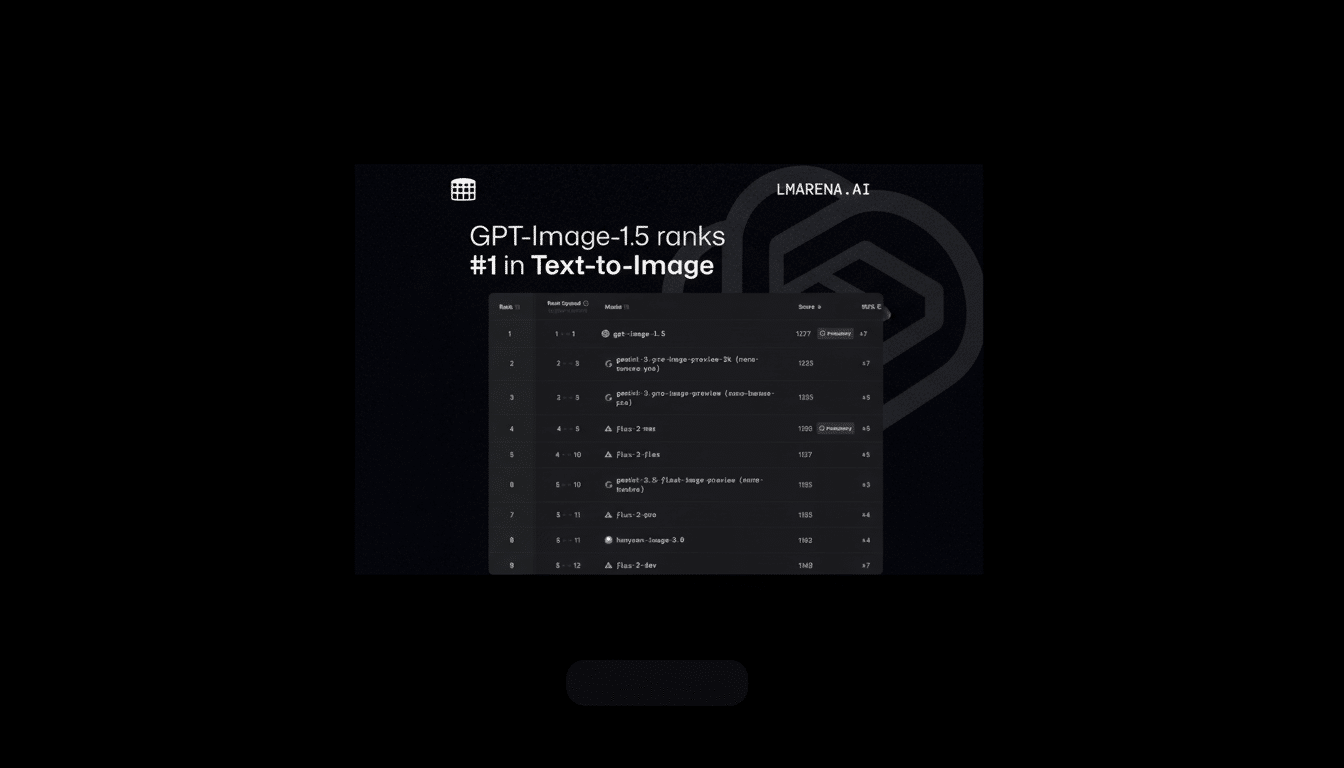
Gemini heat is on as Google’s models pressure OpenAI
The release arrives in a two-week sprint with Google. The recent success of Google’s Gemini 3 (OP2) and its widely shared image model Nano Banana Pro have caused it to top all major community leaderboards such as LMArena across numerous benchmarks, resulting in an “internal code red” at OpenAI. In parallel, OpenAI launched GPT-5.2 to re-establish its superiority in text and multimodal tasks.
OpenAI had been expected to refresh its image stack early next year, but accelerated the timeline, highlighting how fast the competitive baseline is changing.
The firm’s previous big image model, GPT Image 1, dropped in the spring; this follow-on may hint at a lower pacing frequency when it comes to new releases as the industry adopts high-quality, production-grade multimedia generation.
Why iteration quality matters for real production workflows
Prompt-to-prompt continuity still eludes most generators. Creative teams can lock a layout one moment and then watch it subtly change the next, requiring manual touch-ups or reruns. When it comes to advertising and ecommerce, where a product angle, background, and even brand colour need to remain consistent, those variations can mean wasted time and budget.
Provided GPT Image 1.5 produces stable, localized edits, this lowers the cost of variance.
Think: updating the reflection on a watch face without changing the hands, shifting a studio light by a stop while maintaining skin tone, or iterating facial expressions across an editorial storyboard while not changing identity. That’s the difference between something that is a “fun demo” and a “daily driver” for production teams.
More visual responses within ChatGPT for clearer answers
OpenAI also intends to mix in richer images into ChatGPT’s answers, with more explicit source attributions—useful for information retrieval tasks such as those that involve unit conversion, quick comparisons, or sports results where a graph or image beats text. The move is part of a larger trend: Assistants are redefining themselves from chat windows to hybrid canvases that combine text, images, and inline tools.
What to watch next as GPT Image 1.5 expands to all users
Now the key questions are about cost, call limits, and resolution caps on the API to determine whether agencies and app developers can make high-volume workflows work at a reasonable price. Benchmarks established by public evaluators (e.g., LMArena) will quantify the quality of edits, identity preservation, and instruction-following against Google’s current models.
The near-term payoff for creators and businesses is speed plus stability. Attempts to generate faster condense iteration loops; editing becomes increasingly precise in order to keep assets consistent for multi-campaign work. Should GPT Image 1.5 remain open at scale, it would be a significant advance in taking generative images from experiments to everyday production—precisely the kind of momentum we could stand to see OpenAI secure in a Code Red year.