Artificial intelligence is not getting dramatically smarter on its own. It is getting bigger, more power-hungry, and more expensive to build. A new analysis from the Massachusetts Institute of Technology finds that frontier gains overwhelmingly come from throwing more computing power at large language models, not from breakthrough algorithms. That dynamic is reshaping the AI race into a capital and energy contest where access to chips, data center capacity, and power grids determines who stays on top.
Compute, Not Cleverness, Is Driving Gains
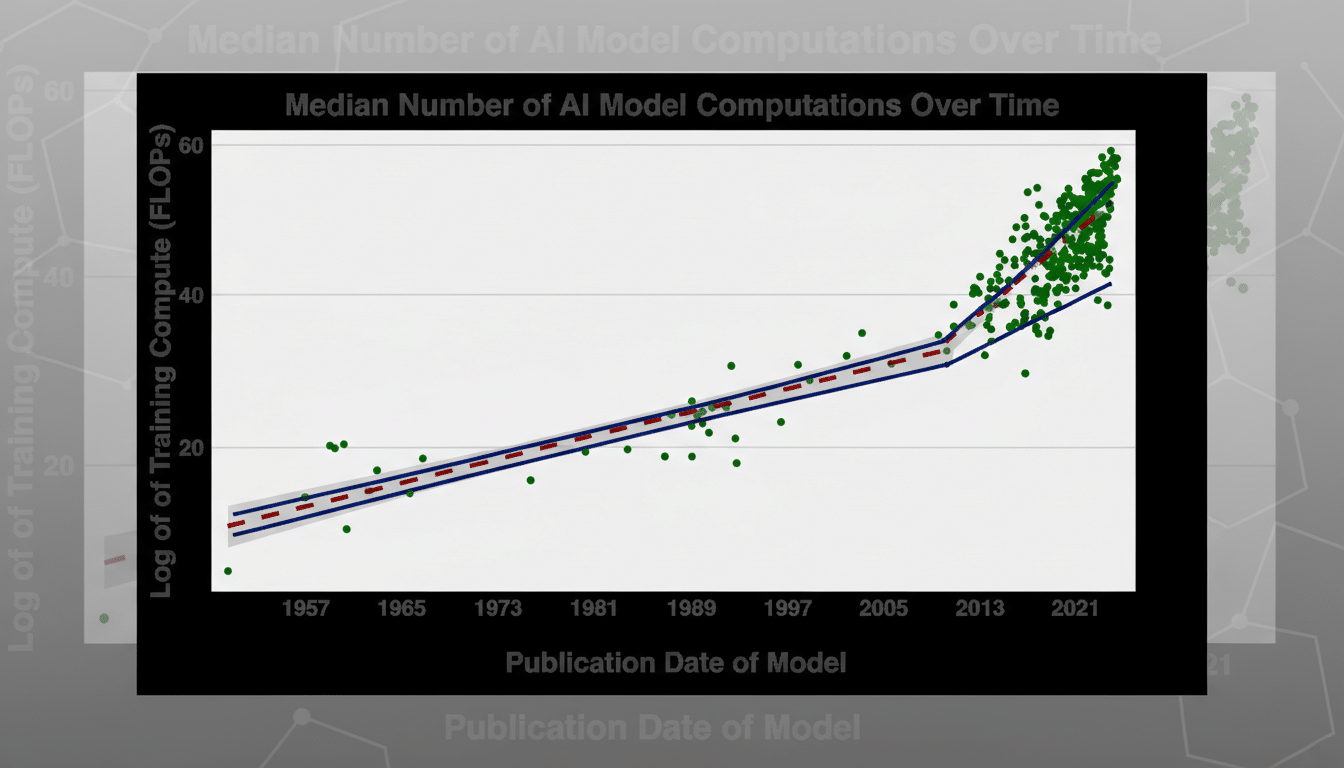
MIT researchers led by Matthias Mertens examined 809 large language models and decomposed their benchmark performance into three drivers: training compute, shared algorithmic advances, and developer-specific techniques or “secret sauce.” Their conclusion is blunt: scale dominates. The strongest predictor of top-tier results is the amount of compute used during training, with only modest uplift from publicly shared methods or proprietary tricks.
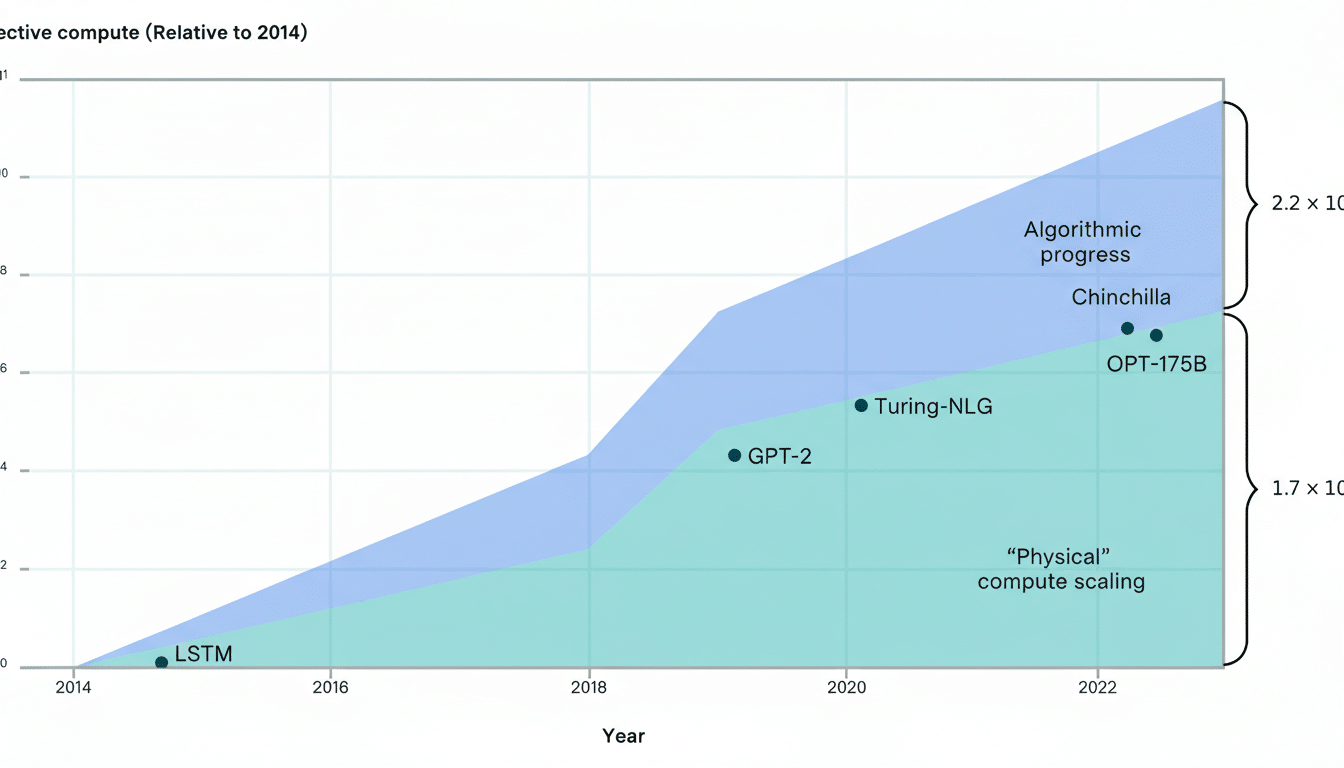
The team reports that a 10× increase in compute yields clear and consistent performance gains across standard evaluations. At the extremes, models at the 95th percentile consumed roughly 1,321× more compute than those at the 5th percentile—an enormous gap that maps closely to leaderboard standings. There is a secret sauce, but it is in the seasoning, not the main course.
That finding helps explain the industry’s behavior: the leaders keep scaling because scale keeps working. The cost is that leadership now depends on sustained access to rapidly expanding compute resources, not just better ideas.
The Rising Price of Power and Chips in AI
Scaling is colliding with economics. Bernstein Research, citing World Semiconductor Trade Statistics, notes average chip prices are roughly 70% higher than pre-slump levels, with premium markups for the highest-end AI accelerators. Memory—especially the high-bandwidth DRAM from Micron and Samsung that feeds those GPUs—has also logged double-digit price increases. Hardware is the new moat, and its walls are getting taller.
Even as each GPU generation grows more efficient, frontier training runs demand ever-larger clusters, faster networks, and denser racks—plus the power and cooling to match. The result is spiraling capital intensity. The biggest platforms are pouring hundreds of billions into data centers, specialized silicon, and grid interconnects. OpenAI’s ambitions, backed by partners and outside capital, are emblematic of the scale of financing now required just to stay in the race.
Energy is the quiet constraint behind the chip story. As model sizes and usage soar, inference becomes a perpetual cost center, not a one-time training bill. Operators now manage tokens per joule as a core efficiency metric, and procurement teams are chasing long-term power contracts alongside GPU allocations. When compute is the product, electricity is the feedstock.
Why Smaller AI Models Are Rapidly Getting Smarter
There is good news below the frontier. MIT’s analysis finds the compute required to hit modest capability thresholds has fallen by up to 8,000× over the study period, thanks to cumulative algorithmic progress and model-specific techniques. In practice, that shows up as better distillation, quantization, retrieval augmentation, and sparsity methods that compress capabilities into smaller, cheaper models.
Open-source players and lean labs are capitalizing on this dynamic. Projects such as DeepSeek and increasingly capable Llama derivatives demonstrate how clever training recipes, data curation, and efficient inference stacks can narrow the gap for many real-world tasks. The frontier may be a compute arms race, but deployment can be a software efficiency game.
What It Means for AI Users and Builders Today
Expect AI pricing to remain volatile and generally biased upward at the high end. When chip prices, power costs, and capital spend rise together, list prices and usage tiers follow. Enterprises should evaluate vendors on total cost of ownership, not headline accuracy—think price per million tokens, latency under load, uptime guarantees, and the energy footprint of sustained inference.
Strategically, a bifurcated market is emerging. Giants like Google, Microsoft, OpenAI, Anthropic, and Meta will push the frontier with massive clusters and custom silicon. Everyone else will win on specialization: smaller models fine-tuned for domain tasks, retrieval-augmented workflows that lean on proprietary data, and hybrid deployments that mix cloud, on-prem, and edge to control cost and latency.
The MIT findings don’t say ideas no longer matter—they say ideas matter most when they reduce the need for raw compute. In today’s AI economy, breakthroughs that turn watts into more useful tokens, or shrink models without sacrificing results, are the real intelligence multipliers. Until then, the smartest thing about frontier AI may be how efficiently it can spend on power.