Google is giving Gemini power users a bigger runway. Paid tiers now come with sharply higher daily prompt caps, split by model, replacing the previous one-size-fits-all pool. The change, first spotted by 9to5Google and confirmed in Google’s own notes to subscribers, aims to make usage more predictable and to match demand with the compute profile of each model.
What Changes For Gemini Subscribers With New Daily Caps
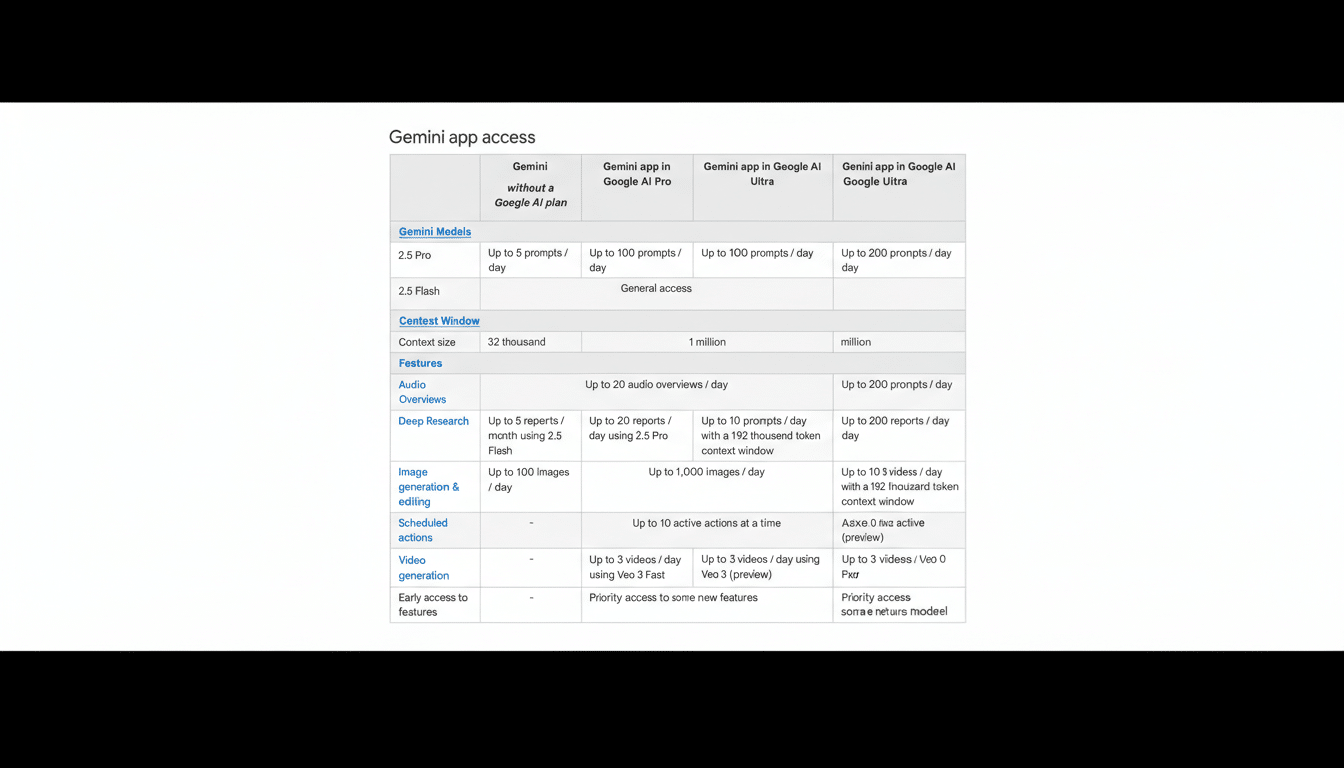
For the $19.99 per month Google AI Pro plan, the Gemini “Thinking” model now allows up to 300 prompts per day. The “Pro” model, tuned for tasks like math and coding, gets its own meter at 100 prompts per day.

For the $250 per month Google AI Ultra tier, the daily limits climb to 1,500 prompts for Thinking and 500 for Pro. That’s a substantial jump from the prior shared caps—up to 4x the total daily headroom compared with the earlier pooled limits—translating to as much as 300% more capacity depending on your workload.
Free Gemini users will also operate under model-specific daily limits. Google says those caps can fluctuate, reflecting system load and ongoing tuning, and the company has not published specific numbers for the free tier.
How The New Model-Specific Gemini Limits Work
Instead of drawing down a single shared bucket, each model now has its own daily counter. If you spend your day composing and analyzing with the Thinking model, it won’t eat into your quota for Pro, and vice versa. This separation is designed to give users finer control over which model they use for which task without worrying about a blended ceiling.
In practice, that means clearer planning. A developer on AI Pro, for instance, could push 80 code-generation prompts with Pro and still have hundreds of Thinking prompts left for product specs, user stories, or data summaries. Under the old shared cap, a burst of coding might have exhausted the day’s entire allowance.
Google has framed the shift as a response to customer feedback seeking more transparency and precision when choosing models. Expect in-product meters and notices to reflect the split, so you know which counter you’re nearing before you hit a wall.
Why Google Is Splitting Gemini Model Caps Across Plans
Different models stress infrastructure differently. A reasoning-heavy “Thinking” run can carry a different compute footprint than a token-intensive coding session with Pro. By allocating per-model caps, Google can better balance load across its TPU-backed data centers while giving users predictable access to the capabilities they value.
It’s also a competitive tactic. As model families diversify, vendors increasingly separate quotas by capability. OpenAI and Anthropic, for example, employ model-specific rate limits and dynamic caps documented in their developer materials. Google’s move puts Gemini in line with that direction while signaling confidence in its capacity—Alphabet has repeatedly pointed to expanded AI infrastructure investment on earnings calls.
What It Means For Teams And Free Users Under Split Caps
For subscribers, the larger, model-specific caps reduce the risk of mid-project throttling and make it easier to assign workflows to the most suitable model. A product team can route exploratory research and writing to Thinking while reserving Pro for code snippets, test generation, and spreadsheet formulas—without one workstream starving the other.
Free users gain clarity but not fixed numbers. Because free-tier limits can change day to day, their experience will remain more variable. That said, the distinct counters should help users understand whether they’re hitting a cap because of the model they chose rather than a hidden blended pool.
The Bottom Line On Gemini’s New Per-Model Daily Caps
Gemini’s higher, per-model daily caps are a quality-of-life upgrade for paying customers and a pragmatic way for Google to manage compute demand. If your work toggles between deep reasoning and code-heavy tasks, the split limits remove a persistent pain point and effectively deliver a larger envelope of usable prompts each day.
Expect further fine-tuning as usage patterns evolve. For now, the message is straightforward: pick the right model for the job, and you’ll get more done before you run into the ceiling.