The AI open-source universe has blown up. Hugging Face itself alone now offers about four million text, vision, speech, and multimodal models under management by a reported community of tens of millions of developers. The issue of choice is no longer a problem — discernment is.
New models, according to Hugging Face co-founder Thomas Wolf speaking in a recent interview on MIT’s “Me, Myself, and AI,” are touching down at an alien-speed frequency on the scale of seconds.
And that flood is reconfiguring how teams evaluate, deploy, and iterate on AI. The winners are those who consider selection an engineering discipline, not a form of browsing.
Here are three concrete paths to cutting through the noise, supported by practices we observe from high-performing AI teams and community benchmarks.
Build a No-Mercy AI Model Selection Framework
Begin by getting down the job to be done and the level of the bar for “good enough.” As a support assistant, this may be first-contact resolution on an unreachable test set; as source code, it could be unit-test pass rates; as a search engine: NDCG or recall; as classification: precision at k-specific recall levels — preaching to the choir. These should be your north stars before you open a model card.
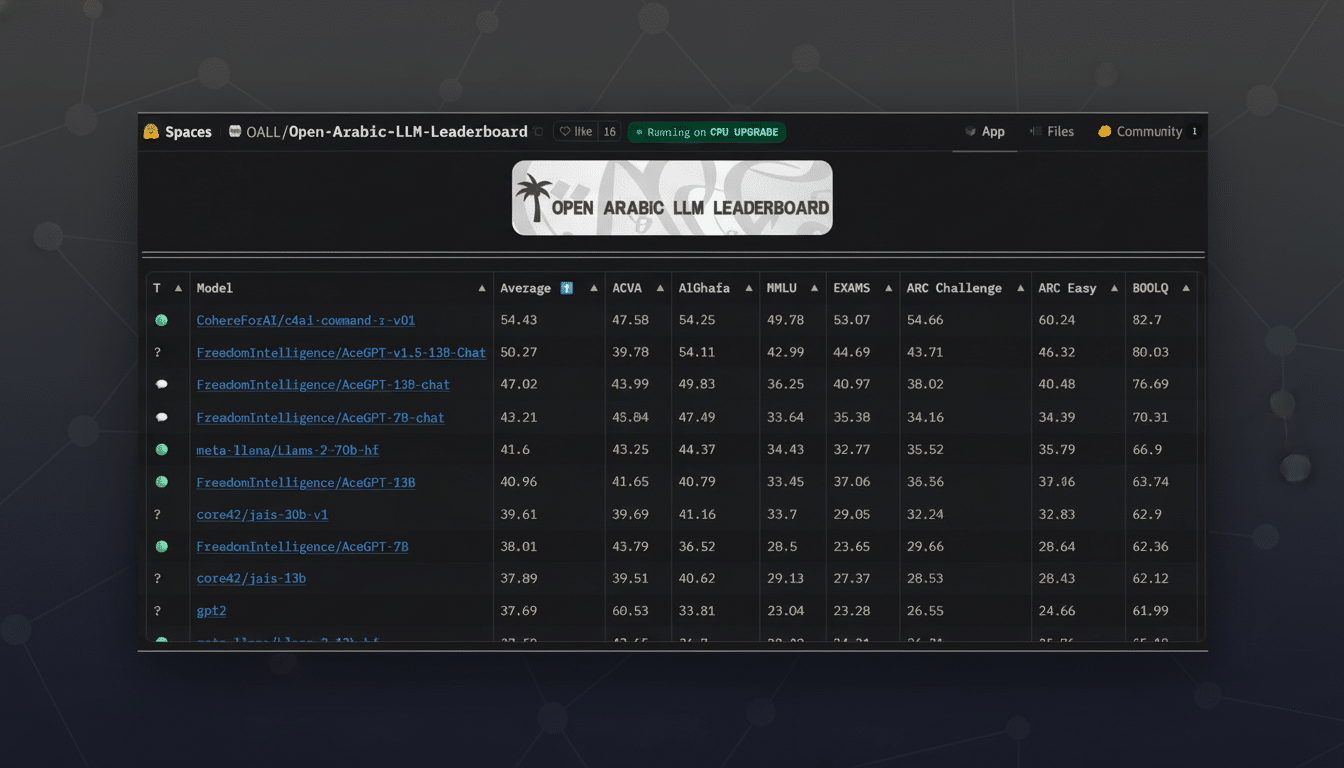
Let third-party reviews help you come up with a shortlist, then do your own. The Hugging Face Open LLM Leaderboard, Stanford’s HELM, and the Massive Text Embedding Benchmark (MTEB) are helpful signals for general performance. If you develop code agents, consider having a glance at repositories like BigCode’s evaluations; for vision, look at benchmarks related to tasks you actually need. But don’t ever stop at public scores — spin up an eval harness on your data and iterate weekly.
Leave room in your budget for latency, memory, and expense as well as quality. A 3B-parameter model on 4-bit likely fits into 2–3 GB VRAM, while a bigger model of 7–8B lands around 5–8 GB; up to massive ones (50–70B) may demand large amounts of memory on the order of tens of GB, even under quantization. Map those facts to your hardware and SLA: expected tokens per day, peak QPS, 95th percentile latency. Scoring for models is based on realistic message lengths and system prompts; the cost in tokens per resolved task is not equivalent to multi-resolution cost.
Align the model with modality and domain. Again, for coding-specific tasks, teams have shown strong results from families such as DeepSeek-Coder and StarCoder2. For multilingual tasks, Qwen models have been proposed. For search pipelines, combine a top MTEB embedding model with a reranker such as BGE-Reranker. For speech and vision, Whisper 6 and Segment Anything are strong baselines. These specializations can easily blow past general-purpose giants for focused workloads.
Lastly, promote licensing to a first-class constraint. Permissive licenses like Apache-2.0 and MIT are not the same as community or research licenses — e.g., OpenRAIL variants, model-specific community licenses, etc. Check commercial use rights, redistribution, and attribution policies before sending it to the factory.
Start Small And Go Local Before You Scale
There is no necessity for a 70B-parameter model for most applications. It is increasingly feasible to make smaller language models (SLMs) that are easy and safe to serve. Recent examples are SmolLM3 at 3B for on-device or laptop use, Mistral 7B as a fast generalist, and Phi-3 and Qwen 2.5 variants for compact reasoning. Start with the smallest model that meets your metric — and if it fails, go up.
Prototype locally to de-risk deployment. Tools like llama.cpp and Ollama make it easy to deploy quantized GGUF/GPTQ/AWQ models on commodity hardware, while vLLM and TensorRT-LLM increase throughput on servers when retaining continuous batching for non-paged attention. You should be able to run a 3B model comfortably on your modern laptop; an 8B model can fit on one GPU (preferably, an 8–12 GB or larger) with reduced precision (4-bit quantization) for interactive workloads.
Fine-tuning beats brute force. Lightweight adapters (such as LoRA or QLoRA) on top of a 7–8B base, pretrained on task-specific, high-quality data, are frequently able to do as well or even better than much larger general models at a fraction of the cost. In production case studies we’ve interacted with, a tuned 8B model has come within striking distance of flagship performance in classification, retrieval augmentation, and form understanding while being 5–10x cheaper.
Follow Trusted Signals And Read Model Cards
With millions of choices, curators count. Track adoption signals: Hugging Face downloads, GitHub issues and commits, and continual iteration from established labs. Listen to those who share reproducible notebooks and transparent ablations. Momentum across months is generally more significant than viral posts over days.
Cross-check claims with independent sources. Use HELM reports for coverage, MTEB for embeddings, MLCommons for performance, and leaderboards from research groups. If a model is too good to be true on one benchmark, verify performance across multiple datasets and your own production-like evals.
Think of the model card as your contract. Watch for summaries of training data, known modes of failure, risk and bias assessments, and restrictions on outside uses. Check out the badge, but be sure to read the license text too. For sensitive sectors, add red-teaming and content moderation layers; open models like Llama Guard and Detoxify can be used to filter prompts and outputs before they reach a user.
The open-source AI swarm isn’t a force to tame — it’s a resource to wield. Describe the goal, start small and locally, and follow reliable signals. Do that, and four million models are an asset, not a bottleneck.