Smartphone makers have spent eight years stuffing Neural Processing Units into handsets, from Huawei’s Kirin 970 to Apple’s Neural Engine and Qualcomm’s Hexagon. The pitch was simple: smarter, faster, private AI right on the device. The reality is messier. Despite soaring TOPS numbers and splashy demos, the day-to-day value of phone NPUs remains narrow, fenced in by fragmented software stacks, thin developer access, and product decisions that keep the best capabilities locked to first-party apps.
Why NPUs Exist In Phones and What They Do Best
An NPU is a specialist: it chews through highly parallel matrix math with tiny data types, excelling at quantized INT8 and even INT4 workloads. That design delivers lower latency and better energy efficiency than running the same inference on a CPU or a power-sensitive mobile GPU. It’s ideal for camera pipelines, on-device transcription, real-time translation, noise suppression, and wake-word detection—jobs where responsiveness and privacy matter.

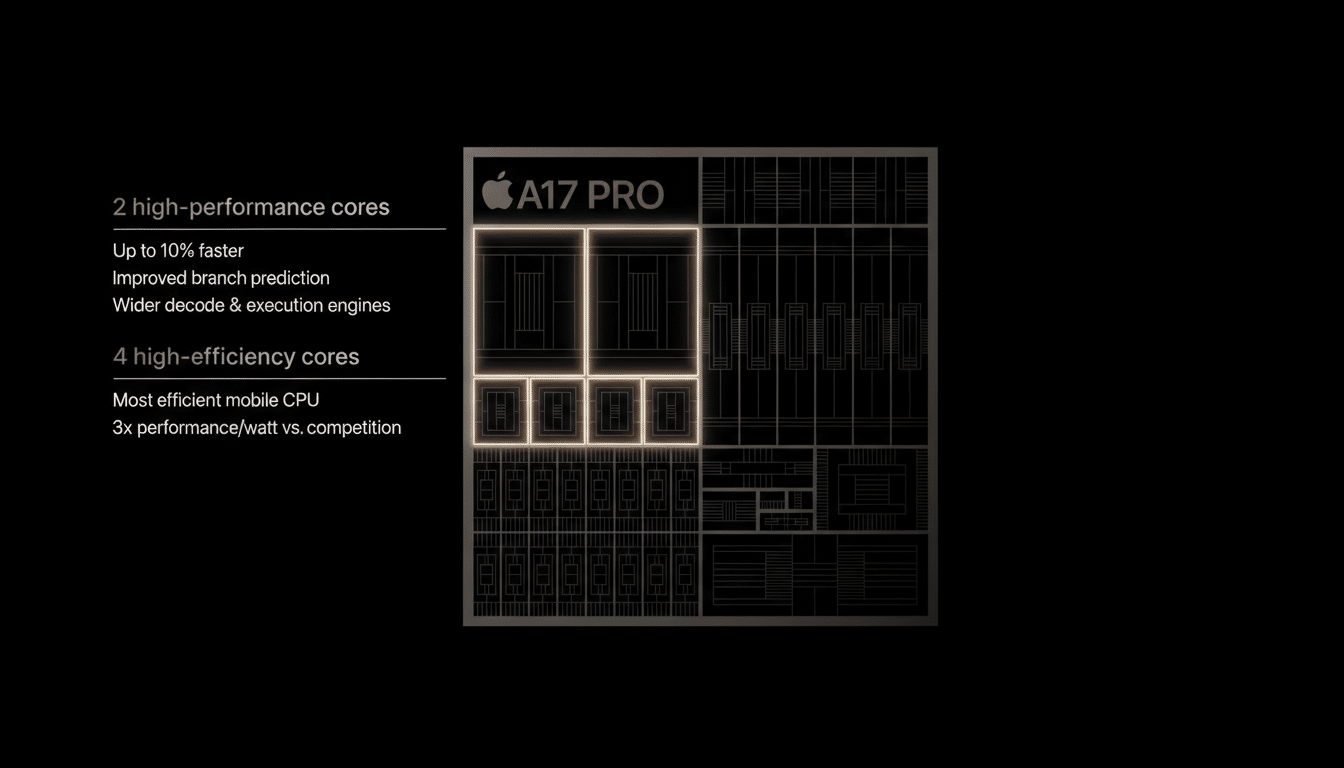
And the silicon has advanced quickly. Apple’s A17 Pro boosted its Neural Engine to tens of trillions of operations per second, while recent Snapdragon and Dimensity platforms tout on-device large language model support and real-time image generation. Yet outside flagship camera tricks and a handful of transcription features, most users would struggle to name NPU-driven apps they rely on daily.
A Specs Arms Race With Few Breakout Apps
Marketing has fixated on TOPS, tokens-per-second rates, and model parameter counts. But software hasn’t kept pace. Counterpoint Research estimates that so-called “GenAI” phones crossed the 100 million unit mark recently—roughly a high single-digit share of shipments—yet the lion’s share of AI engagement still happens in the cloud. It’s telling that most truly novel features, from generative photo edits to summarization, lean on vendor-run services despite local NPUs sitting idle.
Part of the gap is ergonomics. Running a 7B-parameter LLM, even at 4-bit quantization, can consume a few gigabytes of RAM and sustain several watts—unfriendly to small batteries and thin thermals. That’s fine for short bursts, but difficult for prolonged, interactive sessions. So OEMs ration on-device AI to microtasks (instant camera denoise, voice dictation) while offloading heavier lifts to data centers.
Fragmented Platforms Keep Developers Away
On desktops, NVIDIA’s CUDA created a de facto standard that developers can target for performance-critical AI. Mobile has no equivalent. Instead, we have a patchwork: Apple’s Core ML and Metal Performance Shaders; Qualcomm’s Neural Processing SDK; MediaTek’s NeuroPilot; Google’s Pixel-only hooks; and a mix of driver-dependent pathways that behave differently across devices.
Android’s earlier bet on a universal abstraction layer never fully delivered consistent performance, and some vendor-specific SDKs have been discontinued over time, shrinking options further. Even today, many top-tier features are tightly bound to first-party apps. Independent developers frequently default to CPU or GPU fallbacks—or punt to the cloud—because targeting every NPU permutation is risky and expensive.
There are bright spots. Google has been repositioning its on-device runtime to make acceleration decisions at inference time across CPU, GPU, and supported NPUs, aiming to reduce driver roulette. Microsoft’s ONNX Runtime Mobile and cross-platform toolchains are improving portability. But until these layers are stable, predictable, and widely deployed, the safest path for developers is still the one that ignores the NPU.
Hardware Limits Still Matter on Mobile Devices
NPUs aren’t magic. Phones juggle tight memory bandwidth, small caches, and aggressive power budgets. Quantization and operator fusion can shrink models, but accuracy trade-offs and edge cases pile up. GPUs are evolving with better low-precision math, and CPUs keep adding matrix-friendly instructions, narrowing the NPU’s advantage for many mid-size models. In other words, heterogeneous compute is the right goal—but it amplifies the need for a smart software layer to orchestrate it.
Look at imaging, where the pieces align: ISPs, NPUs, and GPUs collaborate under one roof with mature pipelines, yielding Night Mode and portrait effects users love. The same cohesion simply doesn’t exist yet for general AI apps outside OEM walled gardens.
What Would Unlock NPU Potential Across Platforms
First, convergence on a dependable runtime that abstracts hardware differences without hiding performance-critical controls. Developers should be able to ship one model package that runs fast and predictably across Snapdragon, Dimensity, Tensor, and Apple silicon, with the runtime automatically selecting CPU, GPU, or NPU for each subgraph.
Second, durable APIs and tooling. That means long-term support, profiler-grade visibility, and production-ready model conversion pipelines from PyTorch and JAX to mobile targets. Apple’s Core ML already shows how a polished path can lift adoption inside one ecosystem; Android needs a cross-vendor equivalent that sticks.
Third, compelling use cases that do more than repackage cloud tricks. Think local-first assistants that work offline, advanced accessibility features, privacy-preserving photo organization, and multimodal understanding baked into the OS. IDC and other analysts consistently find that users adopt features that are instant, reliable, and invisible—precisely where on-device AI should shine.
The Bottom Line on Underused Phone AI NPUs Today
Eight years in, phone NPUs aren’t a failure—they’re a squandered advantage. The silicon is capable, but fragmentation, shifting APIs, and cautious product strategies keep it from breaking out beyond first-party showcases. If mobile platforms can make acceleration truly portable and predictable, NPUs will finally become what they should have been all along: accelerators that quietly make every app feel faster, smarter, and more private.