OpenAI has published results from a big new experiment that pitted top AI models against each other in an attempt to train them to do real-world work, including translating text and following instructions. The punchline is not a winner-take-all model. Instead, systems fared best on individual axes: Claude Opus 4.1 ranked highest in terms of presentation quality and GPT-5 was most accurate. The results imply that what models should drive, it appears, is product and not brand.
Inside GDPval, the Real-World Stress Test
The evaluation, known as GDPval, gauges performance on 1,320 tasks across 44 occupations highly concentrated in nine industries, which collectively represent over 5% of US GDP. OpenAI relied on the US Bureau of Labor Statistics (May 2024) and the Labor Department O*NET database to replicate work that employers actually pay for.
Tasks were written by experienced practitioners — who, on average, have 14 years of professional experience in their fields — to create deliverables that are realistic: a legal brief, an engineering diagram, an exchange with a customer support agent, or a nursing care plan. GDPval, unlike many benchmarks, populates models from reference files and libraries, and requires multimodal output (slides, formatted documents).
How the Models Were Judged Across Real Jobs and Outputs
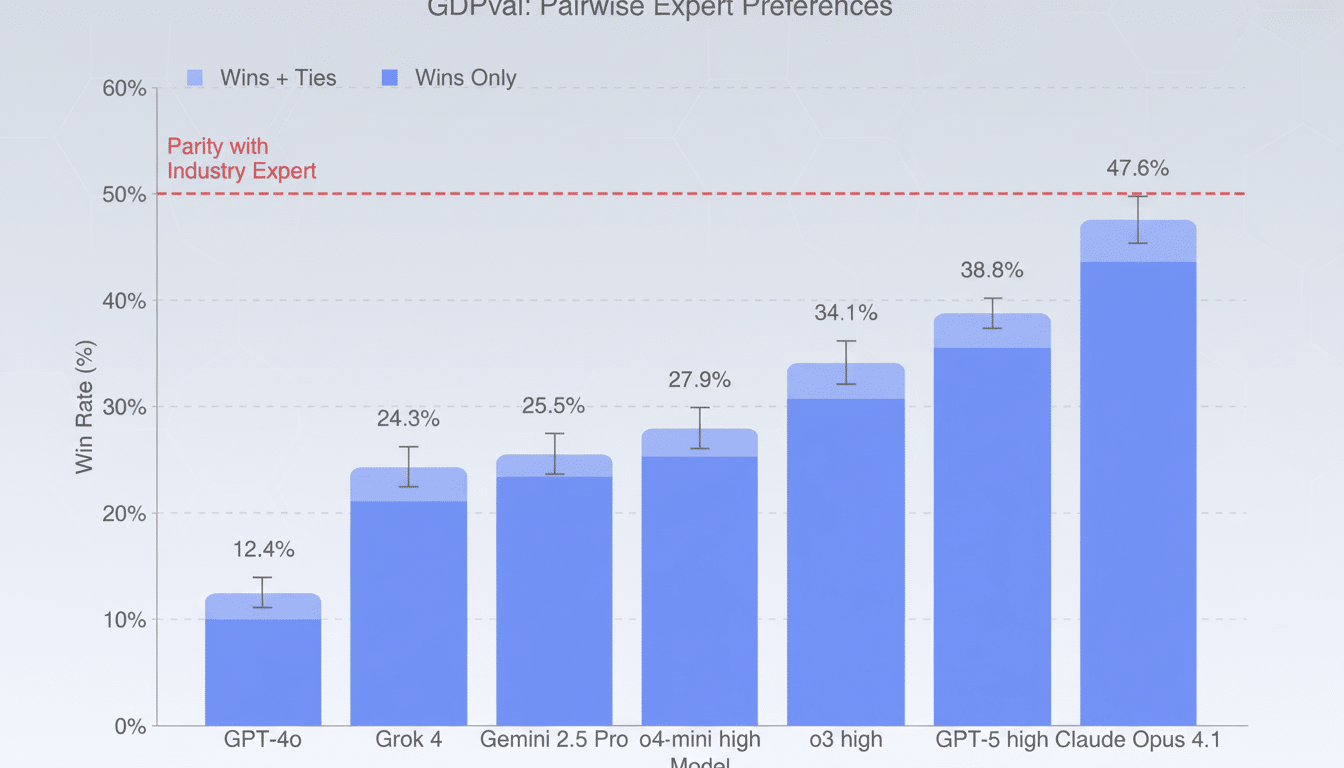
Output was graded by industry experts, blind to the source and comparing model outputs with work produced by people. The fleet consisted of OpenAI’s GPT-4o, o4-mini, o3, and GPT-5; Anthropic’s Claude Opus 4.1; Google’s Gemini 2.5 Pro; and xAI’s Grok 4. OpenAI also tried out an AI “autograder” to predict human scores, but emphasized that having a human editor evaluate the passages is the gold standard.
This is no mere coding or math quiz. OpenAI is positioning GDPval as more wide-ranging and reality-based than domain-bounded economic tests like SWE-Lancer, with a focus on how well model workflows operate end-to-end rather than in sterile prompt–response drills.
Winners, Strengths, and a Surprising Split
Claude Opus 4.1 scored highest overall for performance, particularly in aesthetics — clean slide layouts, well-formatted content, and readable document structure. GPT-5 performed especially well with accuracy of recall and application of domain-specific knowledge. In other words, one model is prone to making client-ready outputs look beautiful; another tends to be more right on the facts.
The generational jump is notable. Performance more than doubled on the task from GPT-4o to GPT-5 in OpenAI’s scoring, highlighting how rapidly the frontier is progressing. That momentum helps to explain why large enterprises are returning to past pilots that fizzled.
The nuance matters for deployment. If you’re a sales team drafting proposals, you might appreciate Claude’s polish; if you’re a legal team vetting citations or a pharmacist verifying contraindications, GPT-5’s precision is probably more what you’re looking for. We also studied Gemini 2.5 Pro and Grok 4, which provide further points, with trade-off options for teams tuning around cost, latency, and ecosystem fit.

Speed, Cost, and the Often-Missed Integration Tax
OpenAI claims its frontier models can carry out GDPval tasks around 100 times faster and for approximately 100 times less cost than domain experts achieve — as measured by raw inference time and the number of API calls required to generate an answer. That headline is catchy — but it leaves out the human oversight, iteration, and integration steps that are necessary to take some of the AI outputs all the way to production grade.
This caveat coheres with larger findings. Just last week, an MIT review found that most enterprise AI initiatives are not meeting the objectives they were set based on the prior year’s results. And Google’s DORA 2020 report alluded that AI is likely to accelerate high-performing development teams and hold back weak ones. The takeaway for leaders: improvements in productivity depend on process maturity as well as model choice.
Limits of the Test, and What Comes Next for GDPval
GDPval grades one-off tasks. It does not gauge the kind of multi-draft workflow, long-running project, or crosstalk exploration that characterizes real collaboration. It also avoids problems of tasks with requirements that change in the middle, or context collected over weeks — things today’s agents still have a hard time with.
OpenAI aims to extend GDPval to additional industries and more difficult-to-automate work, like interactive workflows and high-context work. The organization will release a sampling of tasks for researchers, and suggested that agent-like evaluations are in the pipeline.
Practical Takeaways for Teams Deploying AI at Work
Match the model to the tasks themselves. If shiny executions matter, Claude’s strengths probably shorten edit rounds. If you want to ensure the information is accurate, GPT-5 might sound promising. For mixed workflows, routing (i.e., sending drafting to one model and verification to another) can help.
Design critique that reflects your design work. Give them the same files and formats your teams work with, benchmark both accuracy and presentation, and budget for what I call the integration tax: prompt guardrails, review checklists, and data governance. The most significant savings typically result from feeding the model a first pass of something, and then allowing humans to guide the revisions.
So the bottom line from GDPval is not hype, and it’s also not doom. The gains appear only when organizations engineer the workflow around them, and the top models are becoming competitive with expert work on particular tasks. And as the models separate on strengths — presentation versus precision — the right strategy is pragmatic, not philosophical: get the right tool for each job, a hammer or a screwdriver if that’s what you need instead of trying to pound small screws into wood with a four-pound sledgehammer.