Mistral AI is doubling down on code generation with Devstral 2, a heavyweight coding model targeting production workflows, and a new command-line agent known as Vibe that embraces the emerging “vibe-coding” phenomenon of natural-language-driven software development.
The release highlights the French company’s efforts to close the gap with larger competitors and turn recent research results into tools that engineers will be able to use.
- A push toward vibe coding in developer workflows
- What’s inside Devstral 2, Mistral’s new coding model
- Licenses and open-weight strategy for Devstral models
- Prices that push teams to experiment with repo-scale AI
- Why we ask about the GPU and on-prem deployment needs
- Ecosystem bets and European ambition behind Mistral AI
A push toward vibe coding in developer workflows
Vibe is a CLI to translate repo-wide intent from human-friendly names (file paths) into the dirty work of scanning file trees, poking at Git status and history with sticks, persisting what we learn so you can remember after a coffee break. Say “clean up pagination across services and open a PR” to it, and it should be architected to coordinate code search, edits, tests and versioning without manual direction every step of the way. It’s similar to Mistral’s Le Chat, which holds conversation state, but moves that memory into DevRel workflows where long-lived tasks and statefulness matter.
That direction is consistent with the way developers are increasingly using AI. GitHub’s controlled experiment found that participants completed coding tasks 55% faster with an AI assistant, while community surveys report an increasing majority of developers are practicing with AI code tools. Vibe hopes to turn those personal boosts into a provable team workflow by tightening its integration with repo and shell, not just the editor.
What’s inside Devstral 2, Mistral’s new coding model
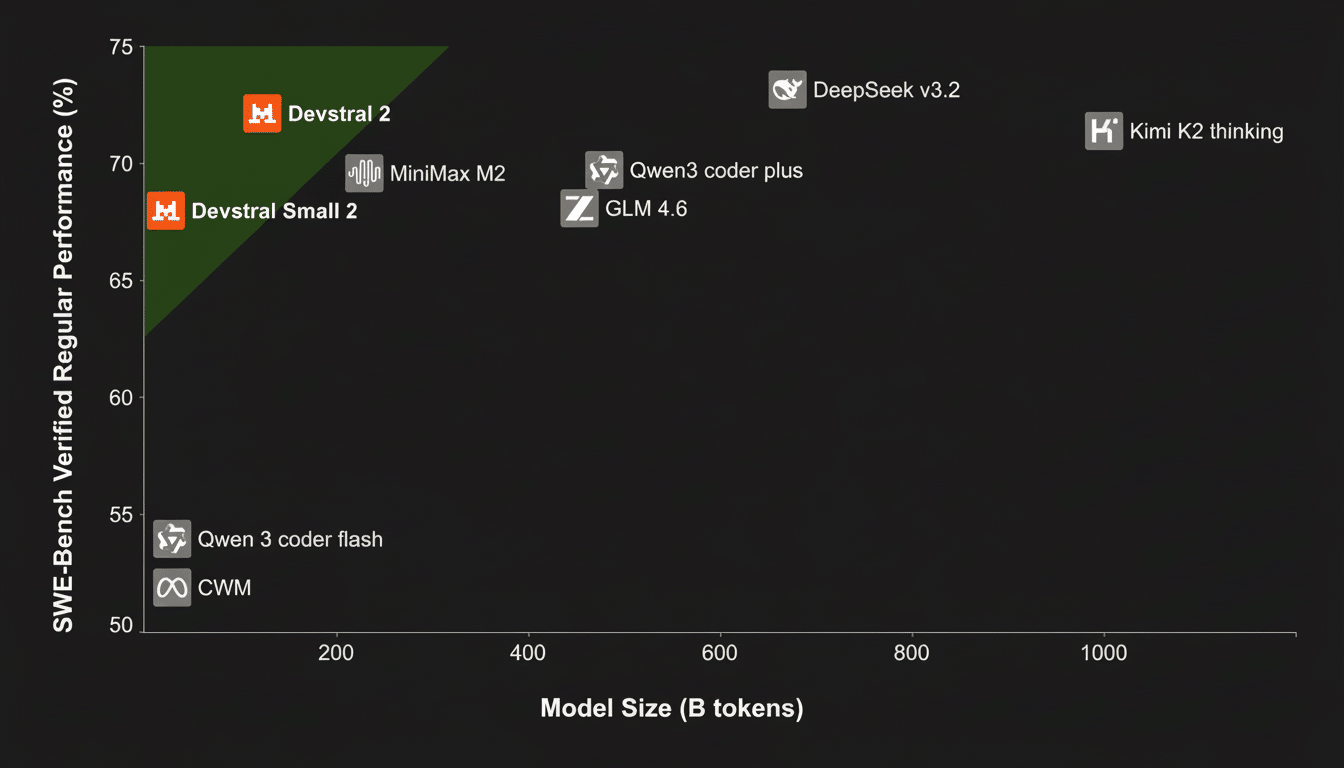
Devstral 2 is a 123B-parameter model optimized for code reasoning (finding failures, etc.) and multi-file changes that can be deployed on at least four H100-class GPUs for on-prem or private cloud use. Mistral is also shipping Devstral Small at 24B (parameters) for local and edge workloads, an option for teams that need fast iterations on consumer hardware or are concerned with inference cost.
The company’s heavy focus is on context awareness at the tooling layer rather than an obsession with inflating model size alone. Vibe orchestrates plugin scanning, Git introspection and persistent memory to provide models the right working set at the right time. In reality, that can be more important than raw benchmarks when you’re refactoring across services, chasing a flaky test that crosses boundaries, or modernizing frameworks where the relevant code isn’t in this file.
Licenses and open-weight strategy for Devstral models
Mistral is open-ish and enterprise-y on guardrails. Devstral 2 ships under a modified MIT license, while Devstral Small is under the Apache 2.0 license pattern, enabling an “enterprify” play: let organizations self-host when they need control and compliance, but retain flexibility around commercial use and redistribution. For a lot of companies, the ability to audit, deploy on their own infrastructure and tune locally is fast becoming a requirement for code-generation systems that will be interacting with sensitive repos.
Prices that push teams to experiment with repo-scale AI
For a limited time, Devstral 2 is free through its API, but after that, it is priced at $0.40 per million input tokens and $2.00 per million output tokens. Devstral Small is $0.10 input and $0.30 output. That’s ambitious against leading frontier models and designed to make repo-scale experiments cheap. As a back-of-the-envelope figure, a 500k-token input analysis with 100k tokens of output would cost on the order of $0.40 on Devstral 2 after the free period—cheap enough to promote daily use on R1 rather than just demo projects [9].
Mistral is also relying on partners to accelerate adoption. The Kilo Code and Cline agent tools are included with Devstral 2, while the Vibe extension is a plug-in secondary to the core of the Zed IDE. The approach is like the way code assistants go viral in the wild: they sink or swim inside a developer’s muscle memory, not on a web demo.
Why we ask about the GPU and on-prem deployment needs
For 123B parameters, the recommended four H100s for Devstral 2 put it in the “serious infra” class. That will confine full on-prem adoption to teams with modern accelerators, but quantization and mixed-precision inference can shrink the footprint quite a bit. (Devstral Small fills the void and is targeting support for laptops and edge servers, providing organizations with a two-tier approach: prototype locally before graduating heavy workloads to data center GPUs as workflows advance.)
Ecosystem bets and European ambition behind Mistral AI
The releases follow the Mistral 3 open-weight family and a significant fundraise which cements the company’s status as one of Europe’s most valuable AI labs. The company has a valuation of €11.7 billion, secured through a Series C investment from Dutch semiconductor giant ASML worth €1.3 billion. That support mirrors Europe’s increasing hunger to create indigenous AI and tooling ecosystems at home, rather than just consuming them.
The larger story is strategic, not architectural. By bundling a repo-native agent together with models ranging from heavyweight to local footprints, Mistral is wagering that “vibe coding” will transition from novelty to standard practice in the workflows of 2025. And if Vibe can consistently follow through and translate intent into multi-step changes in real codebases, with Devstral 2 maintaining quality at a premium-token-discounted cost.