Google has launched Gemini 3.1 Pro, its newest core reasoning model, and early numbers suggest a measurable step up in complex problem-solving. Framed as the company’s most advanced “thinking” model, 3.1 Pro posts strong scores across widely watched evaluations and is rolling out to consumer and developer surfaces starting today.
What Gemini 3.1 Pro Aims to Solve in Complex Workflows
Google positions 3.1 Pro for tasks where a single short answer won’t do—synthesizing multi-source data, explaining knotty concepts in clear language and visuals, and supporting creative exploration. In plain terms, it is built to reason, not just retrieve, and to keep its footing on problems that require several steps before an answer emerges.
- What Gemini 3.1 Pro Aims to Solve in Complex Workflows
- Gemini 3.1 Pro Benchmark Results at a Glance
- How to Try Gemini 3.1 Pro Today on Web and Mobile
- How It Stacks Up Right Now Against Leading Models
- Why These Benchmark Numbers Matter for Real-World Use
- Bottom Line on Gemini 3.1 Pro Performance and Access

According to a Google blog post detailing the release, 3.1 Pro is now the backbone for key Google AI experiences, including the Gemini app and Gemini 3 Deep Think, with an emphasis on more robust intermediate reasoning and practical outputs.
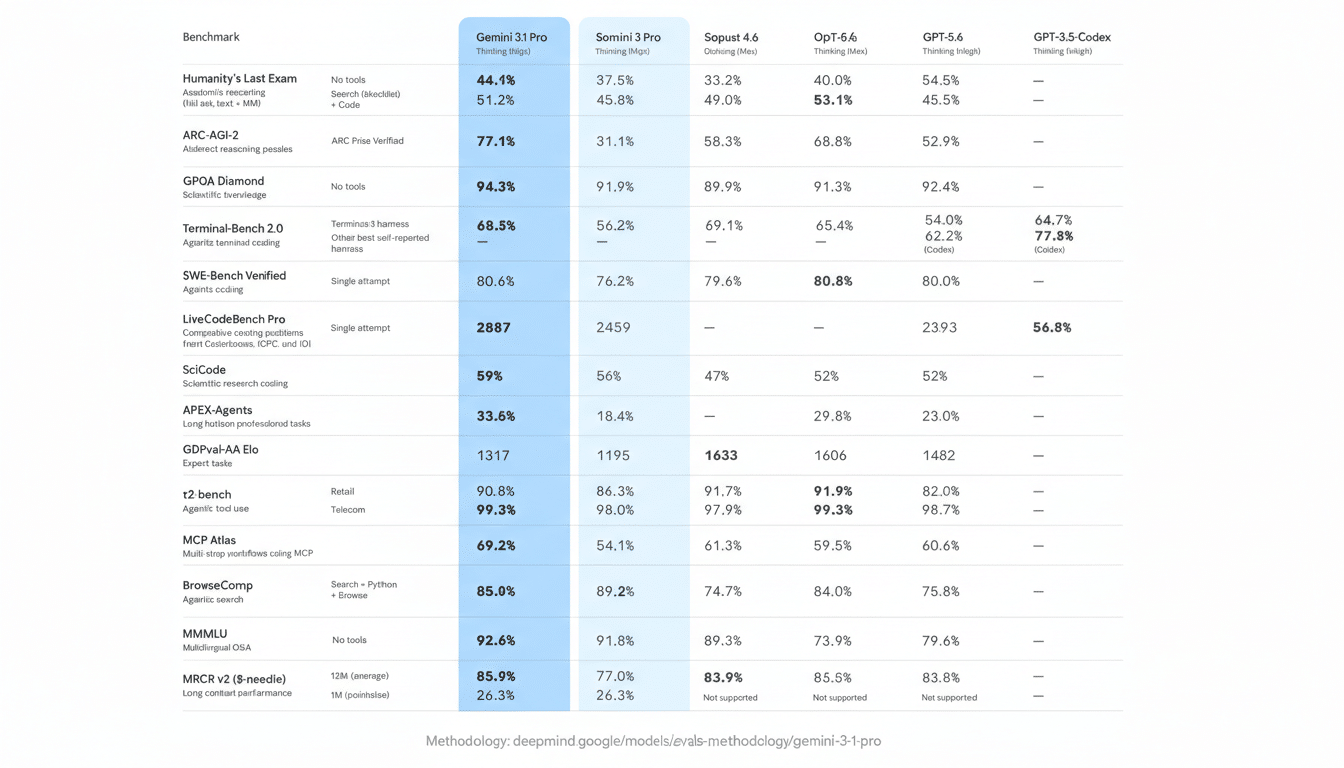
Gemini 3.1 Pro Benchmark Results at a Glance
On high-level reasoning tests, Gemini 3.1 Pro posts gains versus its predecessors and leading rivals. Google reports 77.1% on ARC-AGI-2, a large jump over Gemini 3 Pro’s 31.1% and ahead of Claude Opus 4.6 at 68.8% and GPT-5.2 at 52.9%. ARC-AGI-2 stresses abstract patterns and novel problem formats, so improvements here often correlate with better multi-step reasoning in the wild.
On Humanity’s Last Exam, which bundles difficult, open-ended reasoning questions, 3.1 Pro reaches 44.4%, compared with 40.0% for Claude Opus 4.6 and 34.5% for GPT-5.2. On GPQA Diamond, a rigorous graduate-level science benchmark, it scores 94.3% (versus 91.9% for Gemini 3 Pro, 91.3% for Claude Opus 4.6, and 92.4% for GPT-5.2). These results point to stronger performance on technical reading and knowledge synthesis.
General knowledge remains solid: 3.1 Pro posts 92.6% on MMLU, edging out Claude Opus 4.6 at 91.1% and GPT-5.2 at 89.6%. In software tasks, the picture is more mixed. On SWE-Bench Verified, it hits 80.6% (up from 76.2% for Gemini 3 Pro, and near Claude Opus 4.6 at 80.8%). But on the tougher SWE-Bench Pro (Public), it lands at 54.2%, trailing specialized coding systems like GPT-5.3-Codex at 56.8% and GPT-5.2 at 55.6%. Even Google’s summary acknowledges GPT-5.3-Codex leads on that particular test.
Two takeaways stand out. First, the step-change on ARC-AGI-2 suggests deliberate investment in reasoning rather than narrow instruction following. Second, coding remains a live race: generalized “thinking” models are catching up on verified bug-fix suites, but purpose-tuned coding models still hold edges on the hardest repos.
How to Try Gemini 3.1 Pro Today on Web and Mobile
- Consumer access: 3.1 Pro is rolling out in the Gemini app. Free users can try it with standard limits, while paid tiers such as Google’s AI Pro and AI Ultra expand usage. Expect the model to surface where multi-step planning and long-form responses matter most.
- Notebook LM: Access starts with paid plans. This pairing is notable—Notebook LM excels at structured synthesis across documents, and 3.1 Pro’s reasoning focus should boost summarization fidelity and cross-source grounding.
- Developers and enterprises: The model is available via AI Studio, Vertex AI, Gemini Enterprise, Gemini CLI, Android Studio, and Antigravity. That spectrum covers quick prototyping, production-scale deployment, command-line workflows, and native mobile development, indicating Google wants 3.1 Pro threading through both sandbox and stack.
How It Stacks Up Right Now Against Leading Models
By Google’s published data, 3.1 Pro outperforms Claude Sonnet 4.6, Claude Opus 4.6, and GPT-5.2 on several reasoning and knowledge tests, while conceding ground to GPT-5.3-Codex on the most demanding public coding benchmark. Third-party leaderboards such as Chatbot Arena (formerly LMArena) have recently reflected tighter clustering among top systems, as user preferences swing between raw reasoning strength, style, and tool use.
The competitive signal is clear: the frontier is shifting from factual recall toward resilience on unfamiliar tasks. In that frame, 3.1 Pro’s ARC-AGI-2 and GPQA Diamond gains are more strategically meaningful than a single-digit swing on coding benchmarks.
Why These Benchmark Numbers Matter for Real-World Use
ARC-AGI-2 probes out-of-distribution reasoning, GPQA Diamond stresses graduate-level science comprehension, MMLU checks broad knowledge, and SWE-Bench variants evaluate real-world repository fixes. Stronger scores typically translate to better planning, fewer dead ends, and tighter chain-of-thought internally—without requiring users to handhold the model through every step.
Still, benchmarks are not the job. Deployment context, prompt quality, and tool integration can swing outcomes. Verified subsets reduce noise, while public sets expose brittleness. Teams should validate 3.1 Pro on their own datasets, especially for safety-critical or compliance-heavy workflows.
Bottom Line on Gemini 3.1 Pro Performance and Access
Gemini 3.1 Pro marks a tangible move toward deeper reasoning, with standout gains on ARC-AGI-2 and competitive results across knowledge and coding. It’s ready to test today across the Gemini app, Notebook LM (paid), and Google’s developer platforms. If your workloads hinge on synthesis, multi-step planning, or technical reading, this release is well worth a trial run—just benchmark it against your own reality before committing at scale.