Google has loosened the hose between artificial intelligence and real-world data by releasing a new Data Commons Model Context Protocol (MCP) server that should help AI systems be more based in provable facts and less just churned from cyberspace. For teams that are building training pipelines, evaluators, or domain-specific agents this represents a direct conduit to curated data without the barriers of ETL one would often see.
Debuting in 2018, Data Commons weaves together public datasets from places like national statistics offices, the United Nations, the World Bank, and health and climate agencies available in a unified graph. The new MCP server enables any AI that’s MCP-compatible—regardless of vendor—to query that graph in natural language and receive structured answers. In practice, it converts “show me youth unemployment in Kenya over the past decade” into the precise response, series, units, provenance, and context an agent can use or a model can learn from.
Grounding models to reduce hallucinations
Modern models are often trained on noisy corpora and then tasked with acting as an authoritative source of information for factual questions. It is that disconnect, which enables hallucinations, a weakness identified multiple times in benchmarks like Stanford’s HELM and the TruthfulQA suite. By tapping Data Commons as a canonical, cross-sourced context layer, and indeed the only such layer yet described at Web scale by the authors to my knowledge, developers of domain-agnostic analytical models can decrease error rates in downstream tasks — classification, prediction or LP logic generation — since their agent can go get and cite the actual series behind a claim.
For training pipelines, this offers two advantages. For one, it makes preparing your dataset for fine-tuning easy — instead of writing a bunch of fragile scrapers or reconciling schemas, your team can programmatically fetch consistent time series and geospatial stats with lineage metadata included. Second, it allows for scalable evaluation: one can generate synthetic prompts against the ground-truth statistics to measure numerical reasoning, unit handling, and trend description, closing the loop on model development.
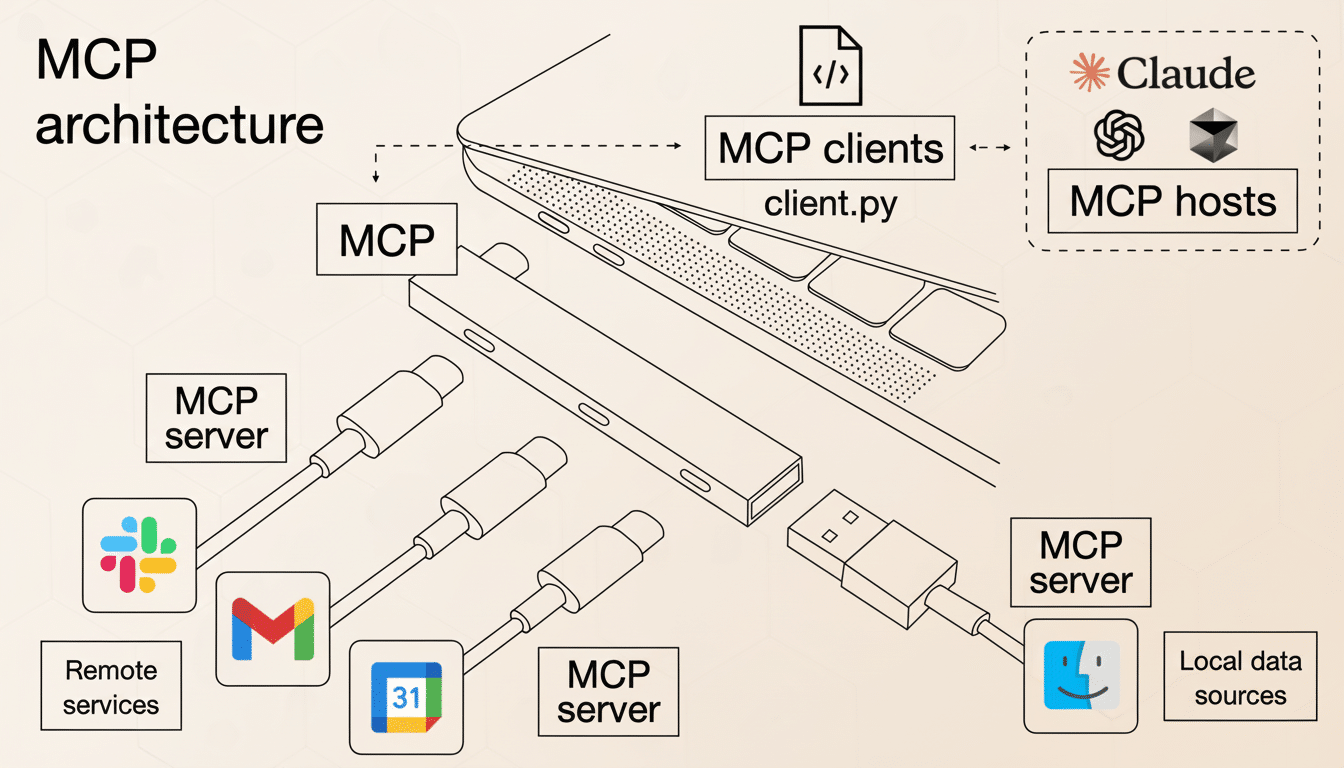
How MCP changes the plumbing of AI data access
Rival’s Model Context Protocol, for example, is an open standard that allows AI systems to communicate with tools, databases, and apps via a shared interface. Since its release, several AI providers have adopted MCP-compatible clients and servers that enable model-agnostic integrations. In Google’s case, the Data Commons MCP server allows searches within (and retrieval from) its knowledge graph; using this functionality, the model is able to choose among variables and disambiguate locations, and data can be normalized — all without hard-coding any API call.
Importantly, MCP supports the tool-use pattern that LLMs excel at: being able to request for clarifications, preview a returned dataset, and then ask for a final package of data with some specific constraints (e.g., in inflation-adjusted values or for particular census geographies or along with appropriate confidence intervals). That turns what were once static, brittle schema-bound queries into a conversational, confirmable process.
Early use cases and partners emerging for the MCP server
Google teamed up with the ONE Campaign to release the One Data Agent, which connects to the MCP server and presents financial and public health indicators in natural language — a model other development agencies and NGOs can follow when they want quick answers from reliable sources. Anticipate similar agents for climate risk reporting, city planning dashboards, corporate sustainability disclosures — where provenance and precision are essential.
Let’s take a few concrete examples: say, a climate analytics application bringing in temperature anomalies and emissions inventories for scenario planning; or a retail forecaster mashing up US census demographics with labor statistics to help calibrate demand models; or maybe something like a healthcare assistant massaging cohort summaries out of standardized mortality and vaccine datasets. In either case, the model’s output is pegged to transparent, auditable numbers.

Developer on-ramps and tooling for Data Commons MCP
Google provides several possible starting points. Developers can test out a sample agent in Colab or make calls to the server from the Gemini CLI, or interface with it in any other MCP-enabled client via our public Python package. Sample code is provided for quick prototyping, and because MCP is vendor-agnostic, a team can wire the same data source into agents driven by different foundation models.
The attraction for ML engineers is speed and repeatability. Pipelines can extract data automatically based on geographies, time frames, and statistical types (keeping their units and definitions). Data lineage is carried with the payload, enabling streamlined documentation and compliance — a feature increasingly being demanded by model governance frameworks of that sort coming from firms like NIST and the OECD.
Caveats: coverage, bias and the cadence of updates
There is no perfect public data platform. Coverage depends on country and sector, and update frequencies can fall behind fast-evolving events. Even official statistics suffer from biases in collection and historical shifts in methodology. Data Commons users have access to aggregated data from reliable sources; however, developers might need to validate assumptions, monitor updates, and manage missingness. Privacy is another reason: access concentrates on the aggregated statistics, not identifiable microdata.
The upside is that provenance is baked in. Each number is accompanied by its origin and definitions, allowing for audit trails. That makes it easier to defend model outputs in regulated environments and to run A/B experiments across such alternative data sets — say, comparing World Bank indicators with national ministry reports — without having to re-write integration code.
Why this matters now for production-scale AI systems
As companies begin to move AI from demo to live production, the bottleneck is moving from model capacity and performance to data quality and governance in overall efficiency.
By coupling an open protocol with a massive curated graph of public statistics, Google is essentially transforming real-world data into first-class context for agents and training loops. It won’t make hallucinations go away entirely, but it shrinks the error bars — and for a lot of production systems, that’s what separates a slick prototype from a dependable tool.