DeepSeek has launched two more AI models, V3.2 and V3.2 Speciale, openly taking on the daily-assistant turf of ChatGPT and pushing more aggressively on complex reasoning. The headline: a speedy, text-first “daily driver” combined with a more rigorous rationale model and some unusually accessible pricing.
Here, then, is what’s new, how it compares to ChatGPT, and how you can play with the models now.
- What to know about DeepSeek V3.2 and its core focus
- How DeepSeek V3.2 stacks up against ChatGPT today
- Benchmarks and reasoning claims for DeepSeek V3.2
- How to experiment with DeepSeek V3.2 on web and API
- Pricing and availability details for DeepSeek V3.2 models
- Key strengths and limitations of the DeepSeek V3.2 lineup
- Bottom line: choosing between V3.2 and V3.2 Speciale

What to know about DeepSeek V3.2 and its core focus
V3.2 (GPT-2) is the most recent large language model released by DeepSeek R1’s creators in China. It’s designed for everyday actions — drafting, summarizing, even code assistance — while naturally embedding tool use in its internal reasoning. In practice, that means the model can determine when it needs to search, execute code, or call a calculator in the course of solving problems.
The Speciale version is aimed at harder reasoning: formal logic, math-heavy prompts, multi-step planning. DeepSeek declares Olympiad-style proficiency and reports good results on reasoning benchmarks. But crucially, the models are open-source, allowing them to be more easily embedded, audited, and run on custom hardware.
How DeepSeek V3.2 stacks up against ChatGPT today
ChatGPT is a closed, multimodal product by OpenAI that fuses text with images, voice, and document tools into a seamless consumer experience. DeepSeek V3.2 is primarily text-first. It excels in code and structured reasoning, can invoke external tools, but lacks some out-of-the-box conveniences such as images or voice.
On publicly available leaderboards such as LMSys Chatbot Arena, newer DeepSeek models trail the very best systems (including the latest releases from GPT and Gemini) but remain competitive on coding and reasoning benchmarks.
Open models that are free of black boxes and can be deployed locally (i.e., transparent usage) may take priority over a small quality gap for builders in some cases.
Benchmarks and reasoning claims for DeepSeek V3.2
DeepSeek says V3.2 Speciale scores in the top echelons of standard reasoning batteries and demonstrates mathematical performance similar to those found at International Mathematical Olympiads. The team cites robust results on the GSM8K, MATH, and coding benchmarks, with additional community replications still underway.
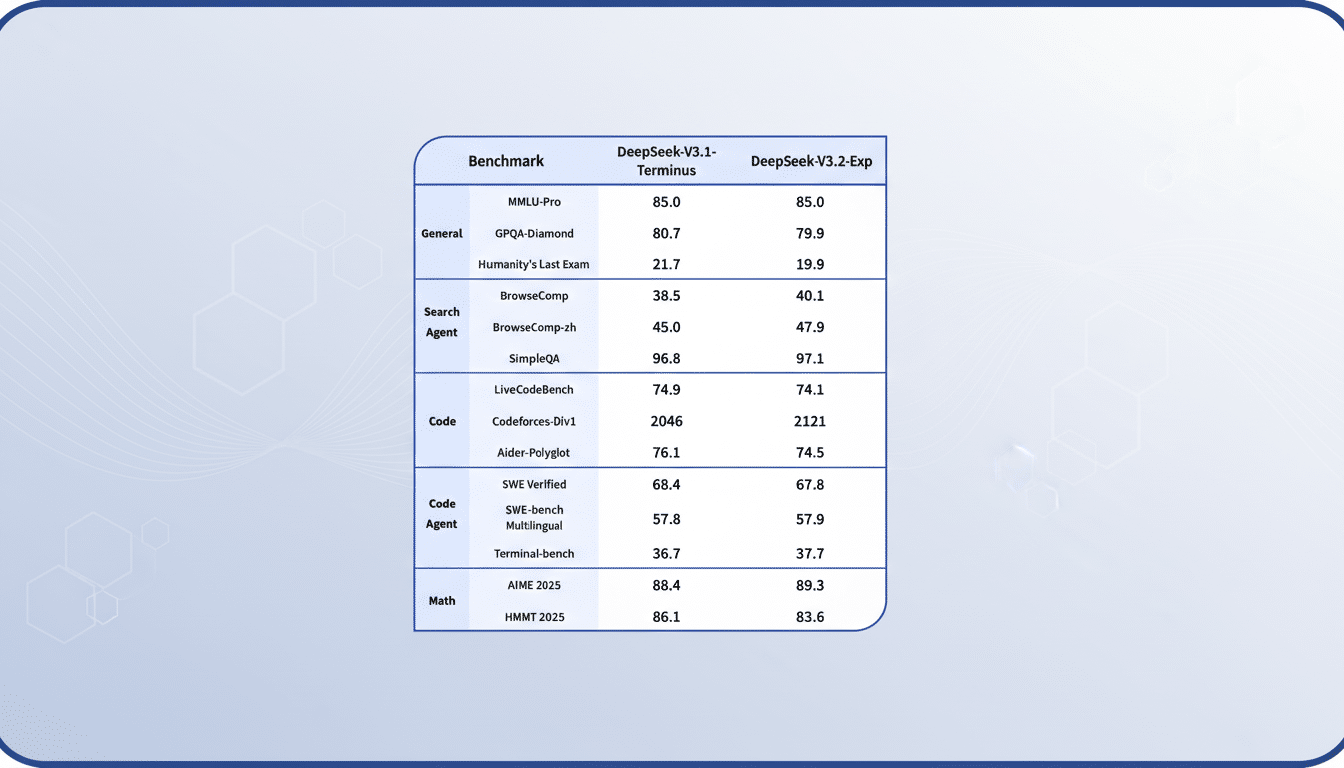
There are caveats: independent researchers warn that leaderboards can be a noisy arbiter. The HAI at Stanford, for example, and groups like EleutherAI regularly highlight risks to the file-sharing system such as benchmark contamination and overfitting. The superior approach would be to use static scores in combination with blinded evaluations and human preference testing, particularly for adoption in enterprises.
How to experiment with DeepSeek V3.2 on web and API
Non-developers can use V3.2 on DeepSeek’s web chat and mobile app. Common use cases include addressing emails, summarizing documents, creating code snippets, as well as guiding users through spreadsheets with sequential explanations.
Developers can call either model via API. V3.2 Speciale is API-only out of the gate. Give this model an API key and choose Speciale as the endpoint; you need to provide instructions on how the tool should call search or a calculator whenever it has determined it lacks some context-sensitive information.
Pricing and availability details for DeepSeek V3.2 models
DeepSeek says V3.2 is available on its website and app up to standard rate limits, with API metering for live production use. That makes it low-risk to try out for teams comparing open models versus closed options.
The company prices V3.2 Speciale at $0.42 per million tokens — about an order of magnitude less expensive than equivalent reasoning models from leading vendors, by DeepSeek’s estimation. And for startups and research groups running long chains of thought, that cost profile can fundamentally alter unit economics.
Key strengths and limitations of the DeepSeek V3.2 lineup
- Strengths: Open-source access, tool integration, good code and math skills, and cheap pricing. The models are also appealing to teams that lean on-prem or need to play doctor with the model’s tool-calling behavior.
- Limitations: Text-first rather than fully multimodal, fewer built-in consumer-facing features compared with ChatGPT, and mixed leaderboard positions against frontier closed systems. Like all LLMs, teams should ensure they test for hallucinations, privacy controls, data retention policies, and safety guardrails before deploying them to production.
Bottom line: choosing between V3.2 and V3.2 Speciale
If you’re looking for a competent, budget alternative to ChatGPT for text and reasoning, DeepSeek V3.2 is an easy recommendation. For math- or logic-heavy work, V3.2 Speciale is the sharper tool — so long as API access and a text-first working environment mesh with your stack.