Anthropic has rolled out Claude Sonnet 4.6 and effectively moved frontier‑class capabilities into the hands of Free and Pro users. The update becomes the default model across consumer tiers without a price increase, adds a 1 million‑token context window in beta, and, in many real workloads, runs faster than the flagship Opus 4.6—all while targeting everyday coding, research, and knowledge work.
What Sonnet 4.6 Changes For Free And Pro Users
The headline shift is access. Sonnet was already the practical, lower‑cost sibling to Opus; with 4.6, it narrows the capability gap enough that many tasks previously escalated to the premium tier can stay on Sonnet. That means more throughput before hitting throttling limits and better price/performance for teams that live in chat interfaces or rely on API calls with strict budgets.
- What Sonnet 4.6 Changes For Free And Pro Users
- Frontier Capabilities Without Frontier Pricing
- Early Signal From Developers Using Sonnet 4.6
- Speed as a Daily Driver for Common Workflows
- Where Opus Still Leads on Precision and Control
- Competitive Context Across AI Model Lineups Today
- What to Watch Next in Independent Evaluations and Use
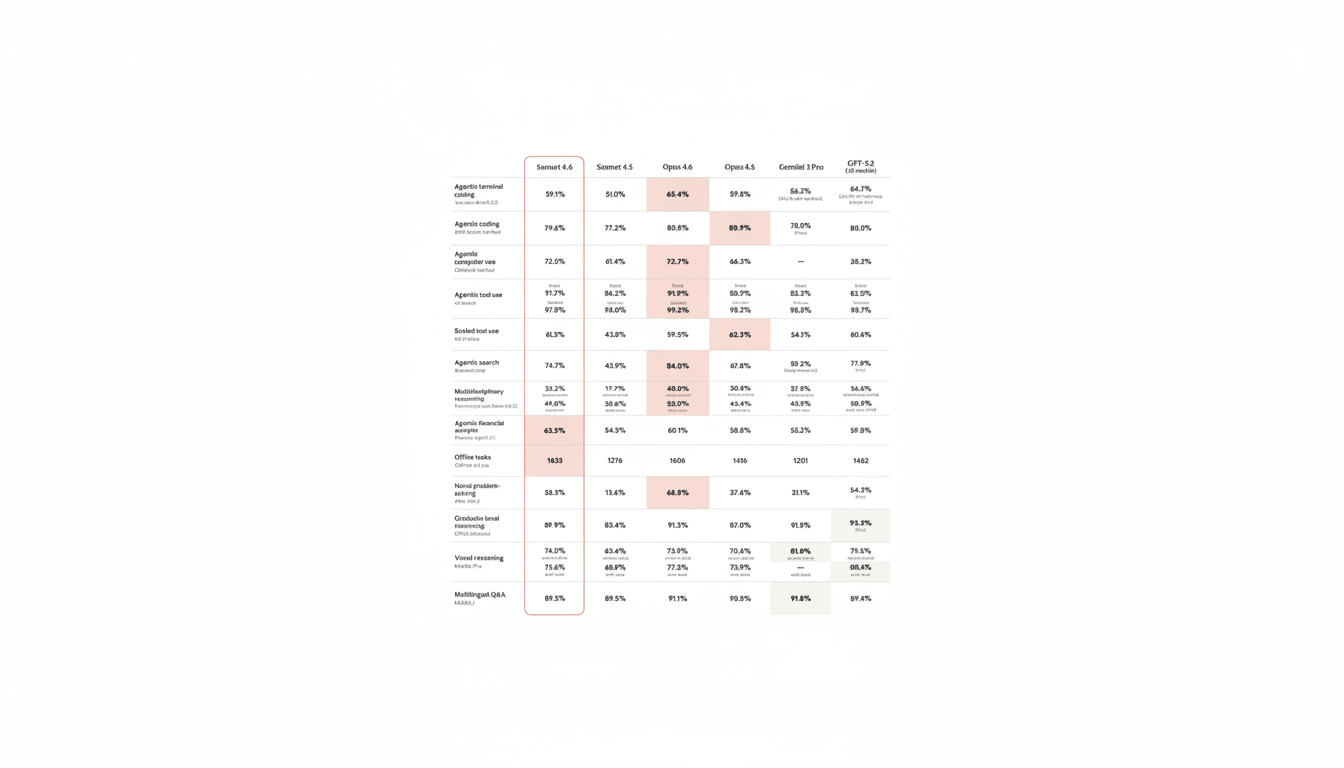
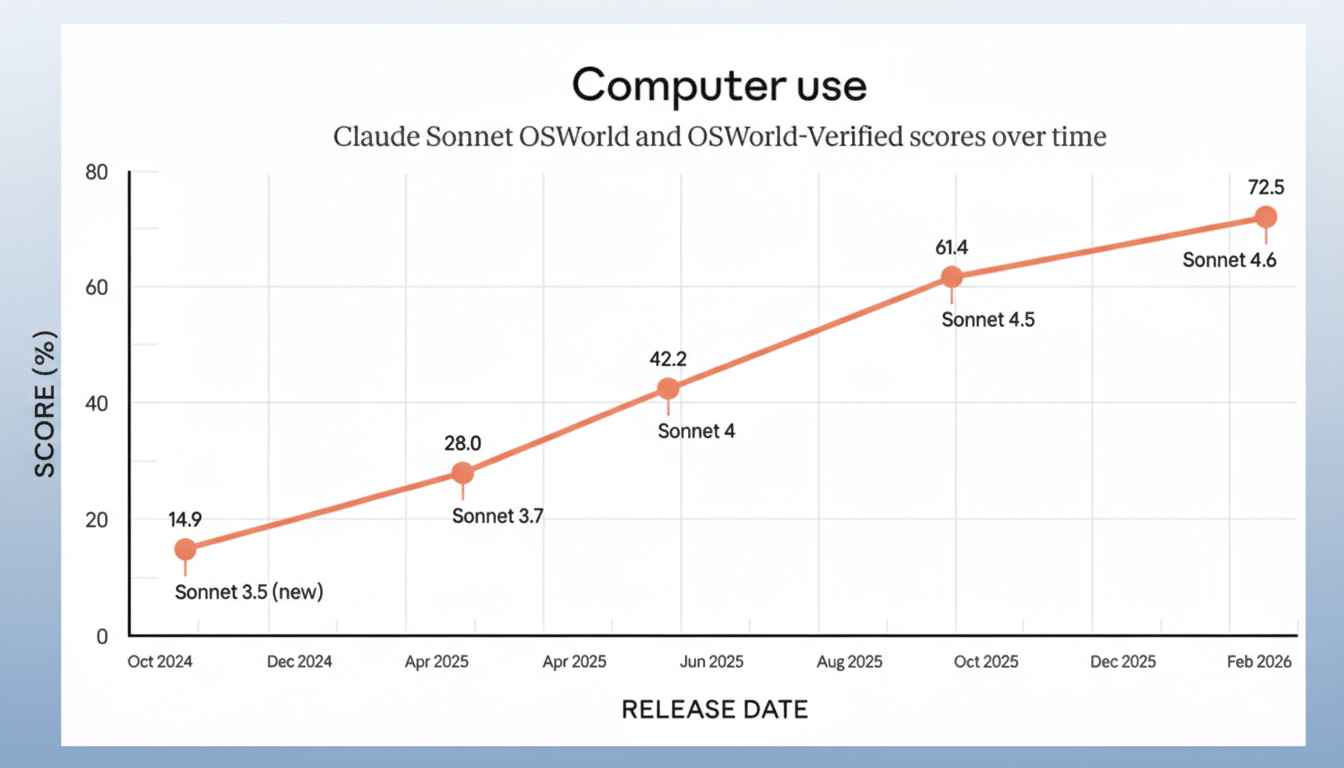
Anthropic positions Sonnet 4.6 as a “daily driver,” and the upgrade backs that up: improved coding assistance, stronger long‑context reasoning, better multi‑step planning for agents, and notably stronger computer‑use skills. In practice, that translates to cleaner diffs, fewer false “done” claims, and steadier follow‑through on multi‑stage instructions that used to require manual babysitting.
Frontier Capabilities Without Frontier Pricing
The 1 million‑token context window (beta) is the marquee feature. It enables sessions that can span an entire repository, a dense RFP with appendices, or a stack of research papers without constant pruning. Crucially, Anthropic says Sonnet 4.6 can reason effectively across that bulk context, which matters more than raw capacity: the goal is end‑to‑end coherence over hours‑long projects, not just bigger input blobs.
For budget‑constrained teams, the economics are straightforward. Sonnet historically carries materially lower per‑token rates than Opus, and Anthropic has not raised prices for this release. If you can keep most work on Sonnet 4.6 and reserve Opus for only the hairiest problems, your effective AI spend drops while turnaround time improves—especially because Sonnet 4.6 is, in many cases, faster than Opus 4.6.
Early Signal From Developers Using Sonnet 4.6
According to Anthropic’s internal testing, developers preferred Sonnet 4.6 over Sonnet 4.5 about 70% of the time. The reasons track with day‑to‑day pain points: it reads context more carefully before modifying code, consolidates shared logic instead of duplicating it, and reduces overengineering. The result is fewer rework loops during long sessions.
In head‑to‑head comparisons against the older frontier model Opus 4.5, Sonnet 4.6 was preferred roughly 60% of the time. Early users also reported fewer hallucinations, fewer premature “success” claims, and better instruction following. While the current Opus 4.6 still leads on the deepest reasoning, that signal underscores how much ground Sonnet has made up for everyday development and knowledge work.
Speed as a Daily Driver for Common Workflows
Speed matters when you are grinding through PR reviews, triaging support tickets, or iterating on prompts during analysis. Anthropic notes that Sonnet 4.6 is often faster than Opus 4.6, making it the pragmatic choice for repetitive, high‑volume tasks where responsiveness and consistency trump absolute peak reasoning depth.
Where Opus Still Leads on Precision and Control
Opus 4.6 remains the right call for precision work: complex refactors across large codebases, multi‑agent orchestration with strict dependencies, or compliance‑sensitive workflows where “almost right” is unacceptable. The smart pattern is tiered usage—run 80–90% of tasks on Sonnet 4.6, escalate to Opus when stakes or complexity demand it.
Competitive Context Across AI Model Lineups Today
The move mirrors a broader industry trend: give mainstream users a fast, capable model for most tasks and reserve the ultra‑heavyweight tier for edge cases. OpenAI has framed similar “fast sibling” dynamics in its lineup; the difference here is subtler marketing and a focus on long‑context reliability over splashy throughput claims. For enterprises evaluating total cost of ownership, this balance is often more meaningful than headline benchmarks alone.
What to Watch Next in Independent Evaluations and Use
Independent evaluations on suites such as SWE‑bench, BigCode’s Eval‑Plus, HELM long‑context tests, and LongBench will help quantify the gains Anthropic reports. Pay attention to agentic computer‑use progress, real‑world reduction in hallucination‑driven rework, and how often teams can keep work on Sonnet versus escalating to Opus. If these trends hold, Sonnet 4.6 won’t just be the “cheap seats” model—it will be the default engine powering most of the workday.