Apple’s prototype model FastVLM for near-instantaneous visual recognition now runs directly in the web browser, no cloud necessary. A lightweight demo hosted on Hugging Face enables your Mac to point its camera at a scene and see captions roll in live, with latency that is low enough to be conversational.
What FastVLM is and why it’s notable
FastVLM is Apple’s visual language model, which has been optimized for speed and size using MLX, the company’s new open machine learning framework that has been tuned for Apple silicon. According to Apple, the method achieved up to 85x speedups on video captioning and more than 3x reduction in model size compared to the VLM-like counterparts in their benchmarks. That combination — low latency plus small footprint — is what opens up the possibility of real-time captions on consumer hardware instead of datacenter GPUs.
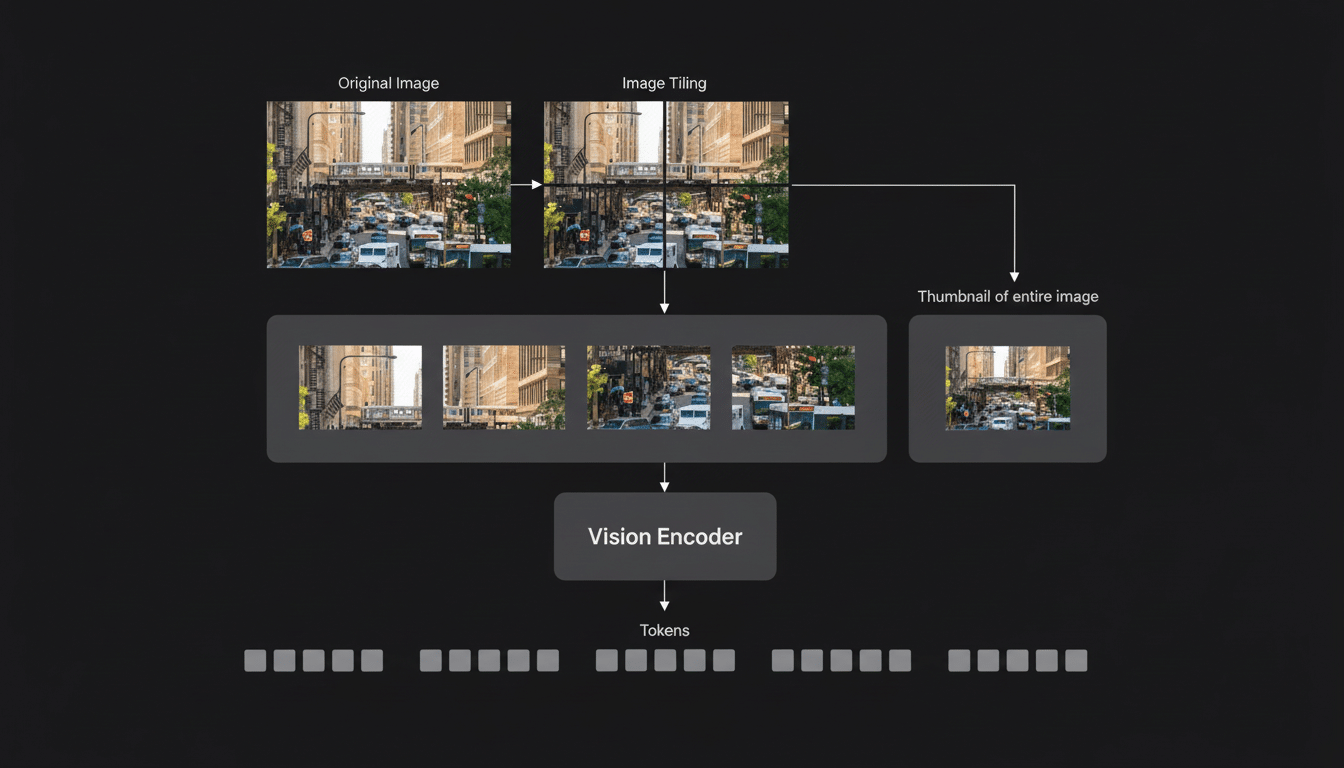
The browser demo demonstrates the 0.5-billion-parameter version, which is the smallest member of the family that also has 1.5B and 7B choices. Its compact model sacrifices a little bit of reasoning depth for responsiveness, which is just what live captioning requires. Bigger siblings offer bolder descriptions, but those ones are probably better suited for the apps or local servers rather than the in-browser experience.
How to try right now
This public demo on Hugging Face runs locally using WebGPU acceleration and quantized weights, so no video frames ever leaves your device. It loads in a couple of minutes the first time you launch it because the model fetches and compiles. From that point on, the captions stream with little delay as you move, gesture or simply look in the direction of something.
Tips for a smooth test: Have a recent version of Safari or a Chromium-based browser with WebGPU enabled, grant camera access and make sure your Mac isn’t set to low-power mode. You can tinker with the prompt at the corner to encourage it to give you attention about actions, objects or cues about safety — and watch the style of captions change on the spot. If you want to stress-test it, feed a virtual camera some fast scene cuts or sports footage, and the model will struggle to keep pace, revealing how it deals with motion, clutter and changes in framing.
Performance, accuracy and limits
Anticipate short warm-up, followed by an enthusiastic, frame-by-frame rundown. On M2 and M3 machines with 16GB or less memory, captions generally will follow casual pace movement and simple interactions. In well-lit settings the model does a consistent job tagging objects, colors and facial expressions and can follow short actions, like “picks up a mug” or “waves at the camera.”
Challenging cases still exist. Fast motion and low-profile lighting can trigger looser diction, and multiple performers in a scene might lose track of whose line it is without the helping hand of additional prompt. Since the demo is optimized for speed, it may sometimes make fast-and-loose guesses as opposed to calculated logic. That’s the trade off at 0.5B parameters, and a reminder that “live captions” here refers to fast descriptive text, not full automatic speech recognition.

Why real-time, on-device captions are important
All running locally on your machine means private by default—no uploads, no waiting on network, and even offline. For accessibility, that’s meaningful. According to World Health Organization, over 430 million people are currently living with disabling hearing loss; fast, on-device visual description can enhance classical captions and assistive tools in classrooms, workplaces and in public.
Creators and editors also benefit. Real-time scene descriptions can help accelerate metadata tagging, B-roll search and content moderation. Furthermore, for enterprise use, on-device processing can aid in checking safety compliance in recorded workflows without compromising sensitive clips to external services. These are the sorts of use cases that Apple’s Machine Learning Research group and the broader accessibility community have been working toward: low-latency, private, reliable.
Under the hood and what’s next
I bet it works in browser because it became possible to use WebGPU for client-side tensor ops and some minimal runtime to run the model graph. MLX, in turn, serves as the basis for native experimentation on Apple silicon — developers praise its memory efficiency and tight Metal integration for delivering real-time throughput without requiring extreme quantization. Together, they present a pipeline from research to hands-on testing that doesn’t rely on cloud GPUs.
If Apple pushes FastVLM into native apps with MLX or Core ML conversions, you can expect higher throughput, longer context windows, multi-modal fusion with audio and depth cues. For bigger editions, 1.5B and 7B, they could be ideal for wearables, vision-based aids or spatial computing applications in which every milliseconds counts — from bike-mounted safety overlays to real-time tutorial nudges.
For now, the gbrowser demo is the simplest way to get a sense of how mind boggling it is. It’s an unusual glimpse at high-quality visual understanding that takes place where your data is, on your device, and points to a near future in which captioning is not a feature you wait for, but a capability that is just there all the time.