Spanish startup Multiverse Computing has released a free, compressed large language model designed to deliver near-frontier performance at a fraction of the footprint. The new HyperNova 60B 2602 model is available to developers on Hugging Face, marking a push to make powerful AI more accessible to enterprises that are constrained by hardware, latency, and cost.
What Multiverse Released With the HyperNova 60B 2602 Model
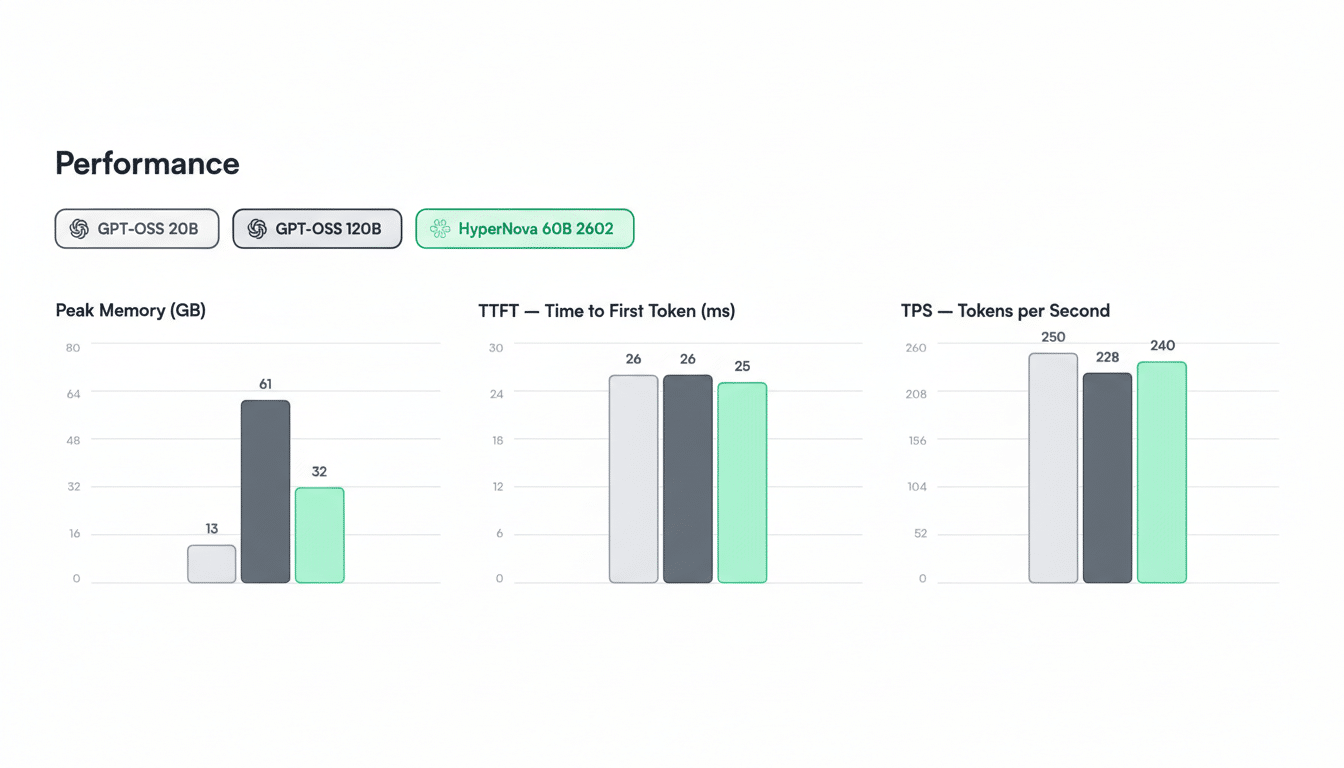
HyperNova 60B is a compressed derivative of OpenAI’s gpt-oss-120B, built with Multiverse’s quantum-inspired CompactifAI technology. The company says the model weighs in at roughly 32GB—about half the size of its source—while using less memory and delivering lower latency during inference. The latest 2602 upgrade strengthens tool calling and agentic coding, two high-cost workloads that strain compute budgets when run on conventional models.
Multiverse plans to open-source additional compressed models over the year to widen coverage across tasks such as code synthesis, retrieval-augmented generation, and structured extraction. For now, free access to HyperNova 60B gives AI engineers a testbed for evaluating whether compressed models can meet production-grade accuracy without the usual infrastructure sprawl.
Why Model Compression Changes the AI Deployment Equation
Compression seeks to preserve accuracy while slashing compute and memory. Techniques like pruning, knowledge distillation, and quantization are already common; Multiverse’s CompactifAI adds a quantum-inspired approach to parameter reduction and representation. The practical upshot is that a 60B-class model with a ~32GB memory footprint can fit on a single high-memory GPU or a modest multi-GPU server, lowering operational and capital expenditure for on-prem and edge deployments.
For enterprises, the economics are compelling. Inference often dominates AI cost at scale, particularly for long-context reasoning, tool use, and code generation. Reducing model size can translate to higher tokens-per-second, fewer nodes required to meet latency SLAs, and better utilization rates—key levers that CFOs and platform teams track alongside accuracy. Analysts at MLCommons and academic groups such as Stanford’s Center for Research on Foundation Models have repeatedly highlighted that throughput and latency improvements are as critical as raw benchmark scores when models enter production.
Rival Benchmarks and Performance Claims to Be Tested
Multiverse contends HyperNova 60B outperforms Mistral Large 3 on select tasks, while approaching the accuracy of much larger models. As always with vendor claims, independent evaluation will matter. Expect head-to-heads across standard suites like MMLU, GSM8K, HumanEval, and tool-use stress tests to determine how close a compressed 60B-class model can get to uncompressed competitors in real workflows.

The positioning reflects a broader European bid for high-performance, sovereign AI. Mistral AI has popularized compact, capable systems; Multiverse is staking out ground with compressed, enterprise-friendly models that can run locally, keeping data residency and governance intact—priorities regularly cited by regulators and customers in the EU and Canada.
Business Momentum and the Push Toward Sovereign AI
Multiverse, founded in the Basque Country and now operating across Europe and North America, counts Iberdrola, Bosch, and the Bank of Canada among its enterprise users. The company raised a $215 million Series B last year with participation from Spain’s Agency for Technological Transformation and has since announced a collaboration with the regional government of Aragón. Backing from regional institutions underscores a policy push to cultivate domestic AI stacks rather than rely exclusively on U.S.-based providers.
While any revenue would be a fraction of OpenAI’s reported $20B ARR, it is directionally aligned with the surge in demand for non-U.S. alternatives that helped push Mistral past $400M ARR. Compression could be Multiverse’s wedge into that market: a way to meet accuracy targets while cutting the total cost of ownership for regulated industries that prefer on-prem or sovereign cloud deployments.
What Comes Next for Developers Testing HyperNova 60B
With HyperNova 60B free to test, developers can benchmark latency, memory use, and tool-calling reliability against their existing stacks. Key diligence points will include license compliance with the base model, reproducibility of Multiverse’s compression pipeline, and transparent evaluation reports. Third-party audits and red-teaming will be important if the model is to see production in safety-critical domains.
If the results hold, compressed foundation models could become a default choice for enterprises that need strong reasoning but cannot justify frontier compute bills. In a market increasingly defined by throughput, cost-per-token, and data sovereignty, Multiverse’s release is a timely test case for whether smaller can truly be smarter at scale.