Microsoft is working extremely fast to reinstate Azure after a considerable outage disrupted central cloud services and consumer platforms worldwide. The business claims it has downgraded to a “last known good” configuration and will reintroduce internet traffic in stages shortly, but intermittent failures will last as systems are restored. The company brought many services back online in fixed stages.
What Microsoft says is happening
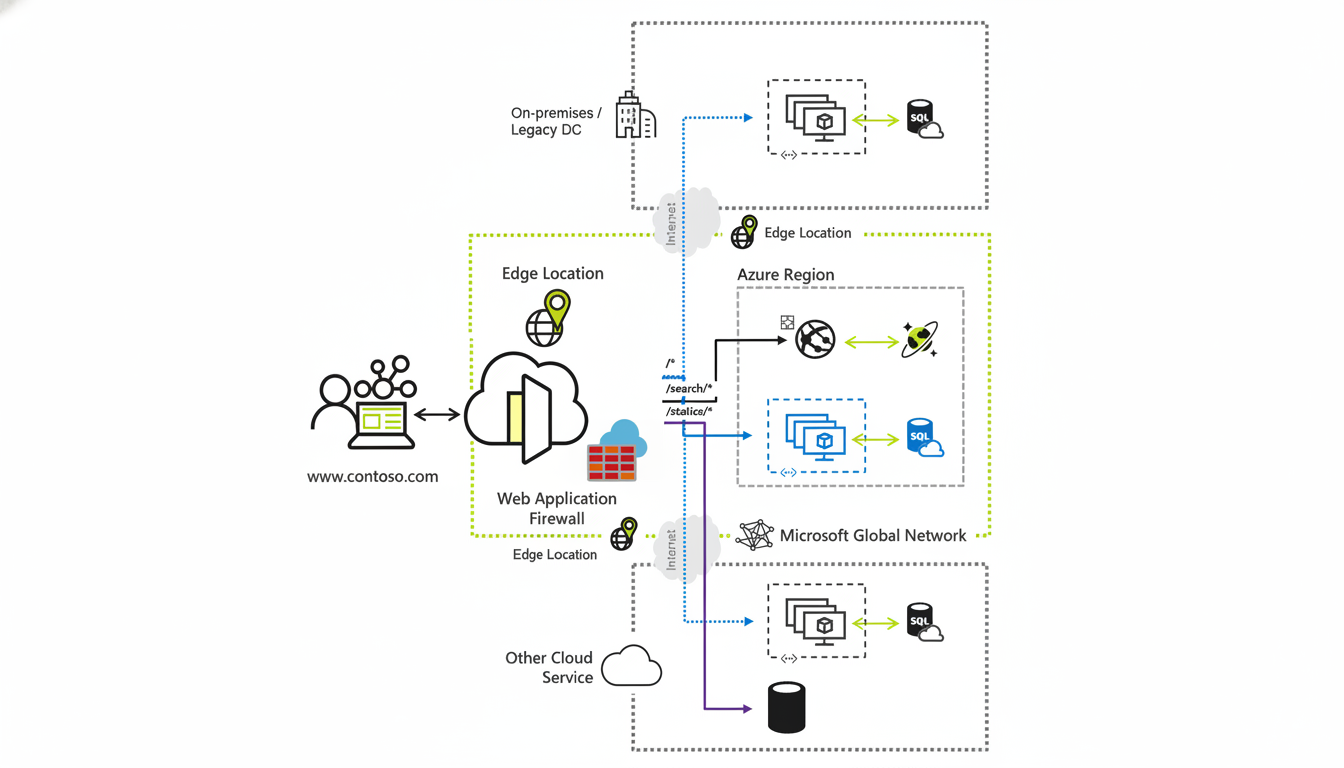
According to Microsoft, the incident resulted from difficulties linked to Azure Front Door, the company’s global edge network that routes and accelerates traffic for applications. Engineers have discontinued configuration changes, downgraded internet traffic to a previous configuration, and have a great number of safeguards during recovery while rolling traffic away from nonfunctioning paths. The iterative process blocks users from changing configurations to minimize hazards of clashing deployments as systems are reintroduced. Microsoft has advised customers with robust business continuity plans to either fail over to source servers or temporarily use Azure Traffic Manager to bypass Front Door.
The post Microsoft Azure Outage Continues To Be Restored appeared first on CRN USA.
Who is being affected by the Azure outage
Essentially in the accumulation, Microsoft has seen an outage that has stretched throughout enterprise and consumer experiences. Microsoft 365 clientele have claimed decreased output and accounting delays; IT executives have complained of interference utilizing Microsoft Intune; gamers have faced service problems on Xbox Live and Minecraft. Aside from big corporate connections, significant brands and public infrastructure have been disrupted, and airlines and telecom operators reported disruptions.
Microsoft confirms the impact on many Azure services:
- App Service
- Azure SQL Database
- Azure Portal
- Azure Databricks
- Media Services
- Container Registry
- Azure Communication Services
- Azure Maps
- Microsoft Sentinel
- Microsoft Purview
- Microsoft Defender External Attack Surface Management
- Microsoft Entra ID
- Azure Active Directory B2C
- Azure Virtual Desktop
- Healthcare APIs
- Video Indexer
Reports and analysis on the outage’s spread
User reports on Downdetector exploded before the initial incident notice was posted. Analysts at Ookla called this a “wide blast radius,” and said it had hit airlines and banks and government agencies. The main reason Azure Front Door created such a large blast radius is that it’s located at the edge of the Microsoft network, serving as the organization’s primary web and API traffic entry point. As a result, a misconfiguration issue at this stage quickly propagates, causing problems for services across most regions even though the compute and storage serving that region remain functional. It’s distinct from a classic single-region outage, which is common in most cloud outages and can be limited to one area.
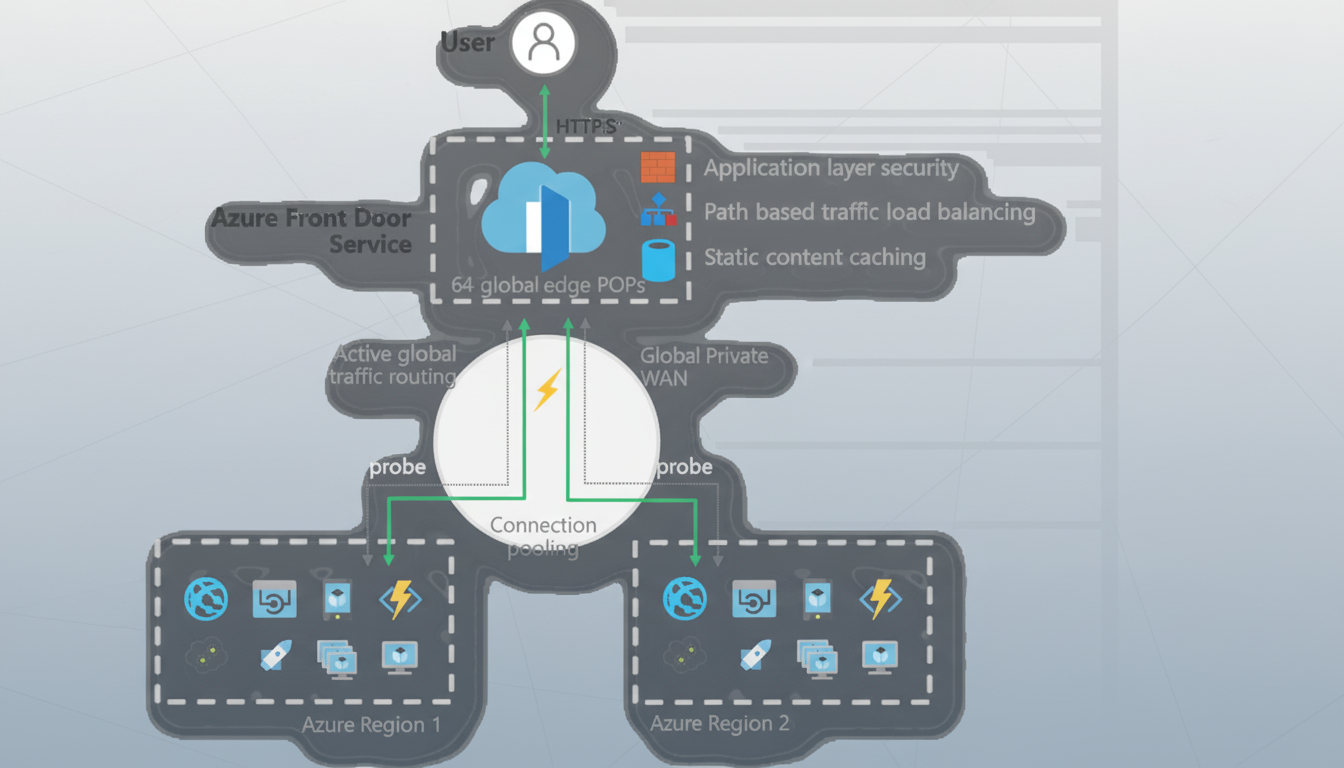
Microsoft’s response, to revert to a previous version of the configuration, is also a standard edge-platform failure response, albeit one that is enhanced by ring-based deployments and change freezes. The difficulty is time: restoring thousands of nodes, repopulating caches, and synchronizing routing tables all need to be done without causing further failures.
If your workloads depend on Front Door, weigh whether you can reroute temporarily to origin servers via Azure Traffic Manager or DNS-based failover. It’s not a small ask; even assuming your health probes, TLS termination, firewall rules, and rate limiting all cooperate, teams need to conduct test runs before shifting traffic. In the case of identity-related errors, reducing non-essential changes and exponential backoff retries can cut user-facing friction during recovery. Firms with multicloud or multi-edge designs may opt to divert a percentage of traffic to alternates. If you haven’t rehearsed that path yet, by most metrics it’s better to hold off and scope for platform stabilization than to dodge a new failover under duress.
The broader risk picture for cloud concentration
Concentration risk in hyperscalers is once again top of mind. There’s no guarantee. Uptime Institute research demonstrates the financial stakes are escalating, with 55% of vital outages currently costing more than $100,000 and 15% exceeding $1 million. Those are rigorous findings for industrial groups such as aviation and finance. The event comes against the panorama of healthy cloud demand. Microsoft recently reported Azure posting almost 40% growth in Q1 and conceded that it faced scalability difficulties linked to AI and cloud workloads. Fast embrace stretches version control and resilience engineering unless linked to rigorous addendums.
How recovery will probably be judged
Key signals to watch for will be the lifting of the configuration change freeze, a steady reduction in authentication and routing errors, and the return of management-plane functions like the Azure Portal and deployment pipelines. Microsoft always follows major incidents with a detailed post-incident review that includes the root cause, the mitigations that have been implemented, and the changes going forward to improve their ability to restrict blast radius in the future. For now, expect a gradual recovery, not an instantaneous return to equilibrium. As traffic is rebalanced and caches regrow, end-user experience will normalize — first for read-heavy workloads, then write- and identity-heavy services thereafter. Businesses that treat this as a true fire drill for their failover runbooks will be strengthened by the experience.