Microsoft’s Azure cloud suffered a broad disruption that knocked out major consumer and business services offline, epitomizing how a solitary setup failure in a worldwide platform can distribute throughout the internet. Microsoft recognized the difficulties linked to Azure Front Door, the front for web applications and APIs distributed globally by the company and started to undo any alterations to preserve traffic and recover accessibility.
What happened during the Azure Front Door disruption
Microsoft claimed that Azure Front Door, which is in charge of load equilibrium, speeding up, and outer-side security parts for consumer applications, was altered inadvertently. They paused further alterations and commenced reversioning to the “final actual” configuration. Recuperation is often phased on a sizable side network: numerous regions and endpoints are returning faster, while this increases worldwide after updates are disseminated.
- What happened during the Azure Front Door disruption
- Who was affected across consumer and business services
- The suspected trigger and why change risk remains high
- How recovery unfolds at cloud scale during rollbacks
- Azure’s market role and why front-door failures ripple
- What customers can do now to minimize service impact
- Recent context on outages across Azure and the industry
- What this means for customers and what to monitor next
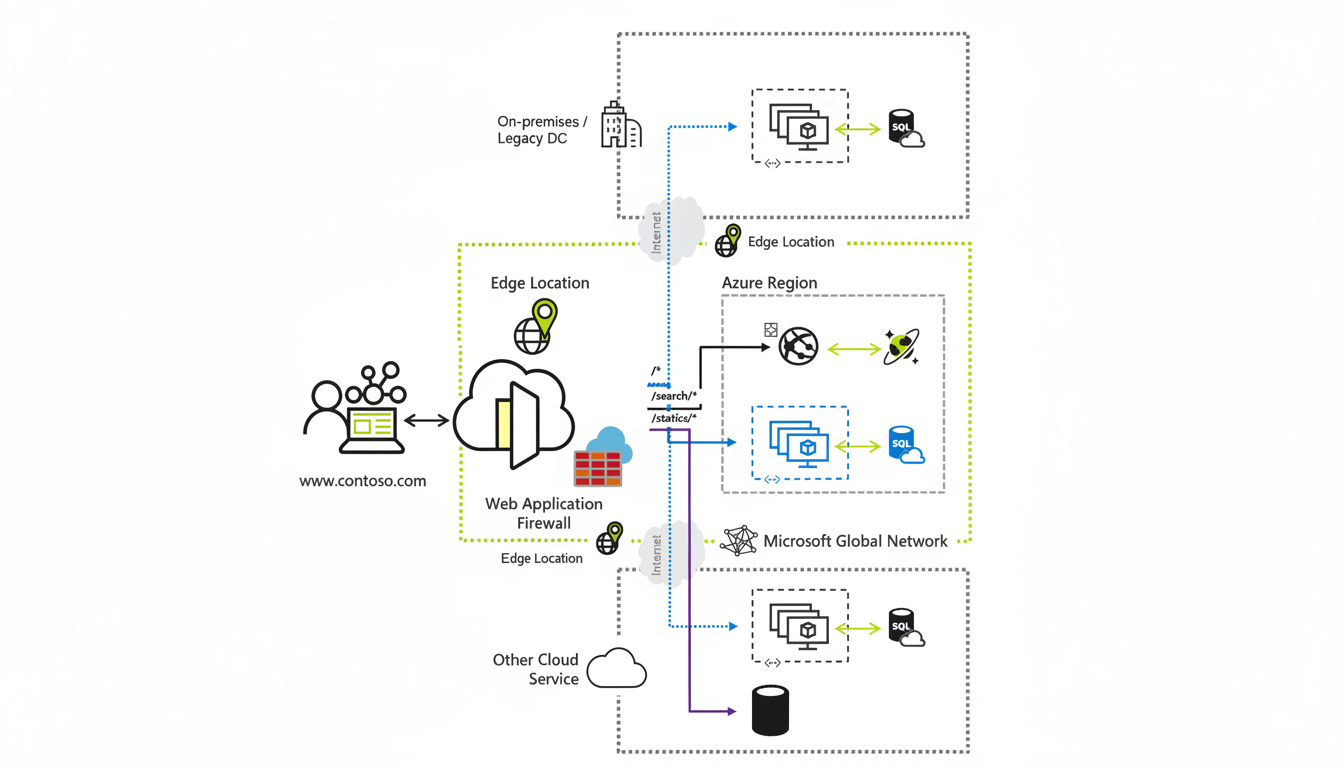
Who was affected across consumer and business services
Because Azure powers many public websites and APIs, most users encountered a malfunction on consumer applications, corporate portals, and gaming services. User reports indicated the consequences for Xbox amenities and Minecraft connectivity, as well as web applications hosted on Azure, including hang-up sessions, sluggish replies, and the 5xx variety of faults. Public monitoring dashboards such as Downdetector had a sharp rise in grievances, while supplier position sheets included partial disruptions and weakened operation.
Azure Front Door commonly fronts production workloads for authentication, content delivery, and microservices; hence, a quickly cascading transient edge misconfiguration: traffic misrouting, cached content going stale, and security policies blocking legitimate requests. Customers that depend on Front Door for origin protection and global routing were particularly exposed.
The suspected trigger and why change risk remains high
Microsoft shed little light into the incident but told me it was due to a configuration change. Industry studies from various organizations like Uptime Institute and Gartner consistently rank change-related errors as leading causes of major outages. The edge and networking layers are particularly risky; clearing a single policy or routing snippet multiplied across hundreds of points of presence can cascade into broad unavailability if safeguards fail or rollout gates are compromised.
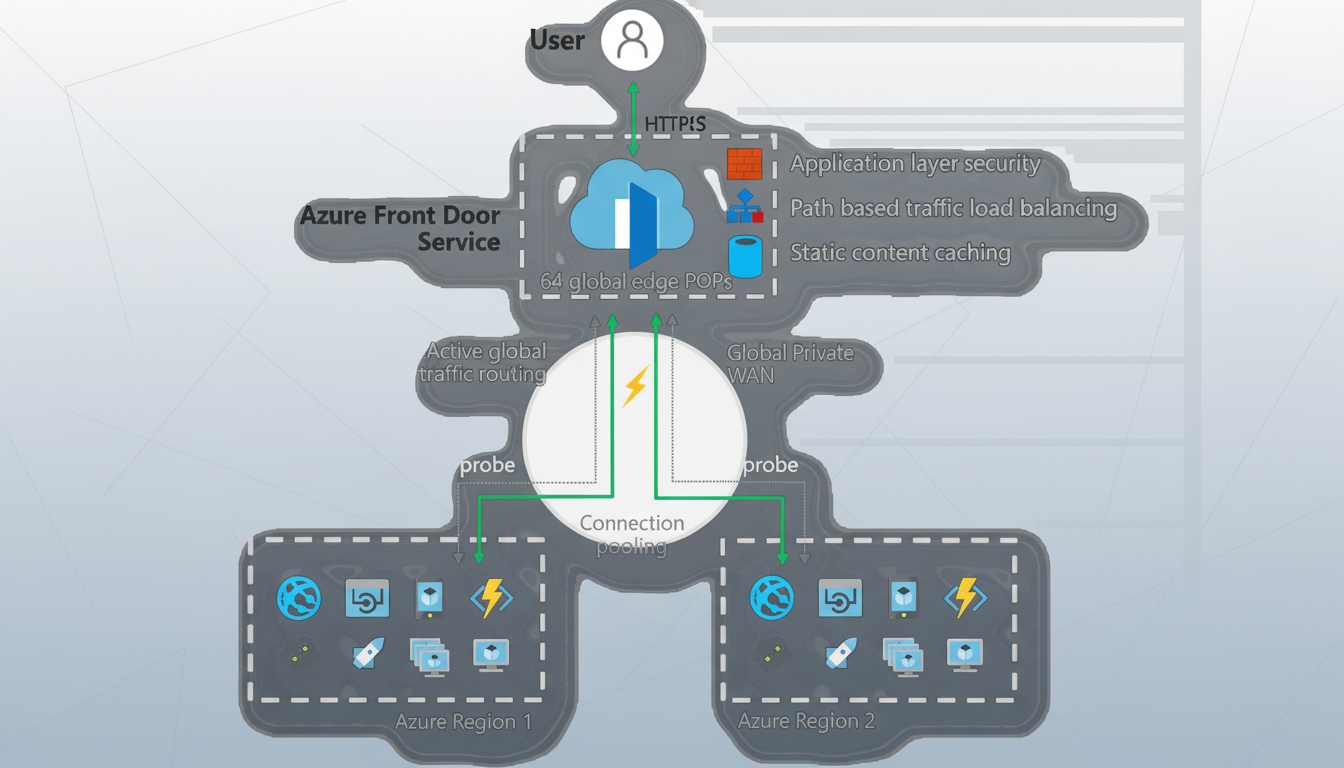
How recovery unfolds at cloud scale during rollbacks
Unfortunately, rolling back at cloud scale is not instantaneous. Edge nodes must receive and apply updated settings, caches must warm back up, and TLS and WAF policies need to re-synchronize. Therefore, users often see a patchy return to normal; some routes healthy, and some still failing, before the performance stabilizes. This recovery pattern is usually reflected in the dashboards of observability firms such as ThousandEyes and internet traffic trackers such as Cloudflare Radar.
Azure’s market role and why front-door failures ripple
Azure is one of the two largest public clouds in the world: according to the Synergy Research Group, Microsoft’s share of the infrastructure services market was somewhere around one-quarter globally, piling in just behind Amazon. When Azure’s front-door layer falters, the results are hard to compartmentalize. Moreover, the incident follows closely on the heels of the prior disruption at a different cloud provider, highlighting a much broader theme: there are only a handful of hyperscalers and their edge platforms that litmus test internet reliability.
What customers can do now to minimize service impact
- Reroute thoughtfully: If you have a fallback CDN or a regional path in mind, you may want to consider a controlled failover, but you must monitor your origin load to avoid an overload. Depending on your precise deployment, some of you can choose to temporarily “turn it off and on again,” bypassing Front Door for critical endpoints and settling for less edge protection in exchange for availability.
- Harden the client: Increase your retry budgets and your timeouts for the calls hitting the affected part of the platform. You should perhaps begin queuing the non-urgent requests rather than letting everything through.
- Communicate clearly: Make certain that your user-facing status pages and your apps are up to date and include a clear, plain-language summary of the problem and its anticipated blast radius. Inside the team, implement a change freeze on dependent systems until the edge layer is stable.
- Review your resilience plans or create new ones: Track and confirm the multi-region and the multi-CDN patterns, pay special attention to how you roll out configuration changes to check for rolling back automation. Azure will issue a preliminary post-incident or an outage report in the near future; track these issues and cross-reference the mitigations with your team’s runbooks (Microsoft, 2021).
Recent context on outages across Azure and the industry
Azure has also now suffered two highly visible outages this month, including impacts to Microsoft 365 and Outlook, and the rest of the cloud industry has seen multiple significant outages across providers this year. Whether the root cause is identity, DNS, routing, or edge policy, the lesson learned is the same: configuration safety nets, rigorous canarying, and blast-radius containment remain the keys to successful internet-scale systems.
What this means for customers and what to monitor next
Microsoft has yet to provide a formal timeline or a full technical root cause. A formal post-incident report is typically issued after engineering reviews to expose the trigger, contributing factors, and hardening steps. Meanwhile, customers should monitor the Azure Status and their own telemetry closely until fully recovered, tracking any remaining regional hotspots that might indicate full resolution.