OpenAI’s GDPval Pits Models Against Experts
OpenAI has released a new barometer, GDPval, that squares its most recent models against experts in economically consequential domains. The rationale is simple: if AI is going to matter for the real economy, it ought to be judged on work that resembles what professionals actually deliver.
The first edition, GDPval‑v0, covers nine major U.S. industries and 44 occupations, ranging from software engineering and nursing to corporate strategy and journalism. For each task the reviewers were choosing between an AI-generated deliverable and a human one, to choose the strongest results. The tasks are slanted toward business-style artifacts — imagine a competitive landscape for last‑mile delivery or a research brief for a healthcare client — rather than academic quizzes.
- OpenAI’s GDPval Pits Models Against Experts
- What the GDPval Results Do and Don’t Actually Mean
- How It Fits With The Benchmark Landscape
- Signals For the Workplace as AI Models Advance
- Methodology Questions That Matter for GDPval
- Why It’s Useful to Examine Through an Economic Lens
- The Road Ahead for Task-Grounded AI Evaluation
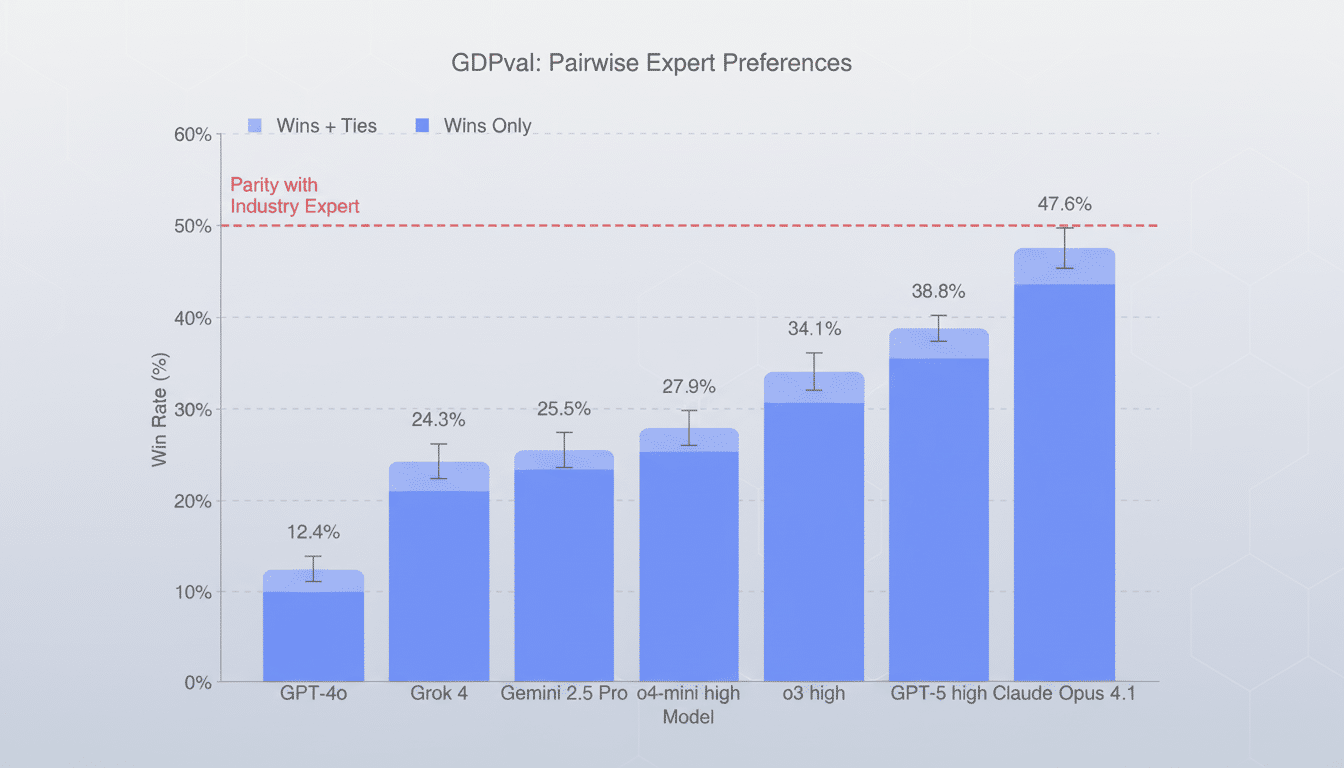
OpenAI announced that GPT‑5 with a compute-enhanced version comparable to GPT‑5‑high achieved at least parity vis‑à‑vis human expert performance 40.6% of the time, according to OpenAI. The Anthropic Claude Opus 4.1 reached a score of 49% in that same comparison. OpenAI contends that Claude’s edge may stem partly from formatting and graphics polish, as well as content degradation rather than fundamentally superior argumentation, a lesson in how task presentation can nudge expert assessments when deliverables resemble client reports.
What the GDPval Results Do and Don’t Actually Mean
GDPval does not argue that AI can perform entire jobs end‑to‑end. The reference point is written work that gets reviewed in a vacuum, not the messiness of what real jobs look like — managing stakeholder demands and negotiating trade‑offs, processing edge cases while satisfying all the rules and responding to feedback over time.
OpenAI recognizes those limitations and says its next versions will have more interactive workflows and a range of tasks. That is crucial. Most professionals are much more than report submitters, and many high‑stakes decisions rely on situational awareness, team coordination and live tool use — areas where large models still vary in quality.
How It Fits With The Benchmark Landscape
Good old-fashioned leaderboards — AIME for competition math, GPQA Diamond (for PhD-level science questions) and MMLU (for general knowledge of the universe) have caused fast progress but are approaching human levels over some subsets. The Stanford AI Index and the HELM assessments from Stanford HAI have advocated for further task‑grounded, domain‑specific evaluations that measure actual utility and robustness.
GDPval works in that direction by focusing on professional deliverables rather than trivia. It is in the same family as emerging task suites such as SWE‑bench for code changes and AgentBench for multimodal tool use. The next frontier will be to move towards realism: access to spreadsheets of records, code repositories, EMR systems or legal/govt checklists, and measure reliability over longer chains of action.
Signals For the Workplace as AI Models Advance
But even with caveats, the findings suggest near‑term leverage. In a controlled environment, AI can already draft market scans, summarize discovery calls and structure investment memos that any human can sit down with and polish. That squares with M.I.T. research finding that professional writing time was cut by 37 percent when workers deployed big models, quality improvements accumulating among the less experienced users.

For employers, the short‑term play is augmentation rather than replacement: standardize prompts, define review checklists, and decide which deliverables you are safe to delegate. For the workers, that edge is becoming a discerning editor — someone who can steer a strong first draft through to become a truth you can trust, and catch hallucinations, thin evidence or misapplied frameworks that lead people toward false conclusions.
Methodology Questions That Matter for GDPval
Several design choices will influence how seriously industry takes GDPval.
- Reviewer rigor: Were comparisons blinded, how many raters scored each task, and what inter‑rater agreement did OpenAI see?
- Rubrics: Did graders have a rule of thumb to prefer reasoning quality and citations over stylish polish and charts?
- Access to tools and fairness: Could models use external tooling, and how was computational budget managed across systems, especially vs. the “GPT‑5‑high” variant?
- Safety and compliance: In regulated verticals like healthcare and finance, small factual errors or unsupported claims can have outsize consequences, so the severity of errors is as important as average win rate.
Why It’s Useful to Examine Through an Economic Lens
But by grounding tasks in industries that account for a big portion of GDP, OpenAI is attempting to link advances in model performance with measurable economic value, not just benchmark bragging rights. That focus contrasts with analyses from groups including the OECD and McKinsey, which project significant automation potential in roles such as clerical work, customer support and analytical writing but slower movement around physical work or highly interpersonal labor.
This economic lens also illuminates the distributional effects: when AI raises the floor on routine analysis and drafting, what becomes scarce in a world that is not optimally built around machine intelligence are those aspects of work for which judgment is at a premium; presumably domain expertise, relationship management and data access. That could narrow skill gaps in some jobs while raising the bar when it comes to final‑mile decision making.
The Road Ahead for Task-Grounded AI Evaluation
The computer says GDPval will grow to include work performed in interactive workflows, more occupations, and deeper domain toolchains. Independent replication by academic labs and industry consortia — à la NIST’s Trustworthy AI efforts or the Partnership on AI — would increase confidence, particularly if tasks and scoring guides are public and reproducible.
If future versions demonstrate reliable wins on complex, multi‑step work to tight error bounds, the conversation will move on from “Can models write good reports?” to “What to redesign in what part of what job?” The headline, for now, is obvious: GPT‑5 is competing with expert humans on a meaningful slice of professional production output and the threshold for what counts as state‑of‑the‑art slid toward the way work actually does happen.