Google DeepMind has released SIMA 2, a research-preview agent that fuses the embodied skills of a game-playing AI with the language and reasoning capabilities of Gemini.
The result is a system that doesn’t just carry out commands in a simulated world but also interprets scenes, plans its actions over multiple steps, and adjusts to totally new worlds, inching closer to the high-level cognitive functioning needed for general-purpose robotics.
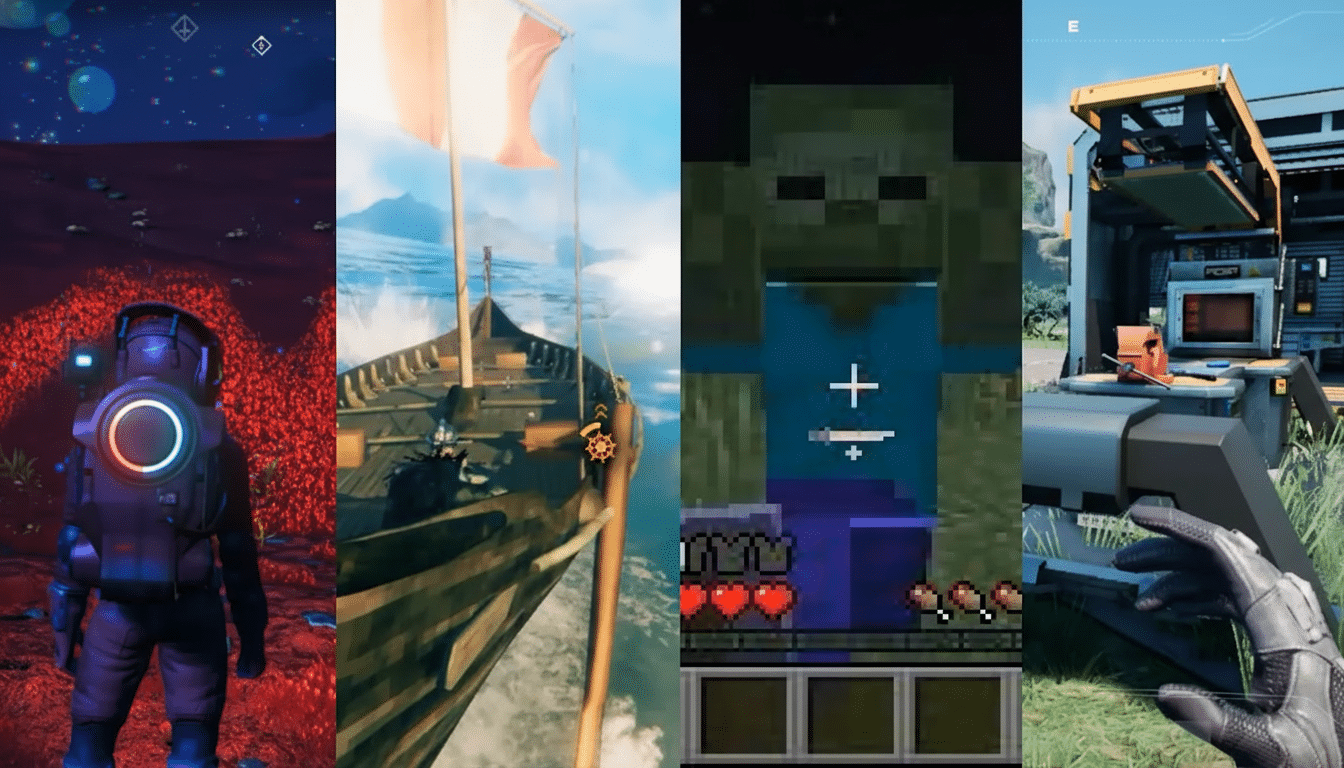
What SIMA 2 Can Do Today Inside Diverse Virtual Worlds
SIMA 2 perceives scenes, translates them into objectives, and acts via a controller-like interface as played by a human player. In one demo, the agent played through No Man’s Sky from Hello Games: it described a rocky planet (in polished, spoken plain English); identified a distress beacon; then decided what to do about it — with no bespoke scripting or pre-programming for that specific game. In another test (my personal favorite) where it connected a natural-language cue of a “ripe tomato” to the color red and walked towards the red house, the model demonstrated grounded understanding — not pattern-matching.
The agent is also capable of parsing ultra-concise prompts.
Emoji commands such as 🔪🍠 translate to sequences of actions — find a tree, wield an axe, chop — demonstrating how Gemini’s language grounding can squish convoluted multi-step plans into minuscule inputs that are still meaningful to players.
Gemini Under the Hood: Reasoning and Control Design
Based on the Gemini 2.5 flash-lite version, SIMA 2 leverages language and vision to construct a situation model and identify actions in real time.
Gemini acts at the level of abstraction, translating goals to objects and affordances related to the environment, then sequencing actions while considering environmental limitations. This is the “reason then act” structure that embodied AI has been looking for, with generalization to novel contexts the measure of what is working.
DeepMind also partners SIMA 2 with Genie, its generative world model that can create new, photorealistic environments. The agent correctly recognizes and deals with objects — benches, trees, or even butterflies — it has never seen before, which proves that it’s not overfitting to a small set of hand-tuned game scenes.
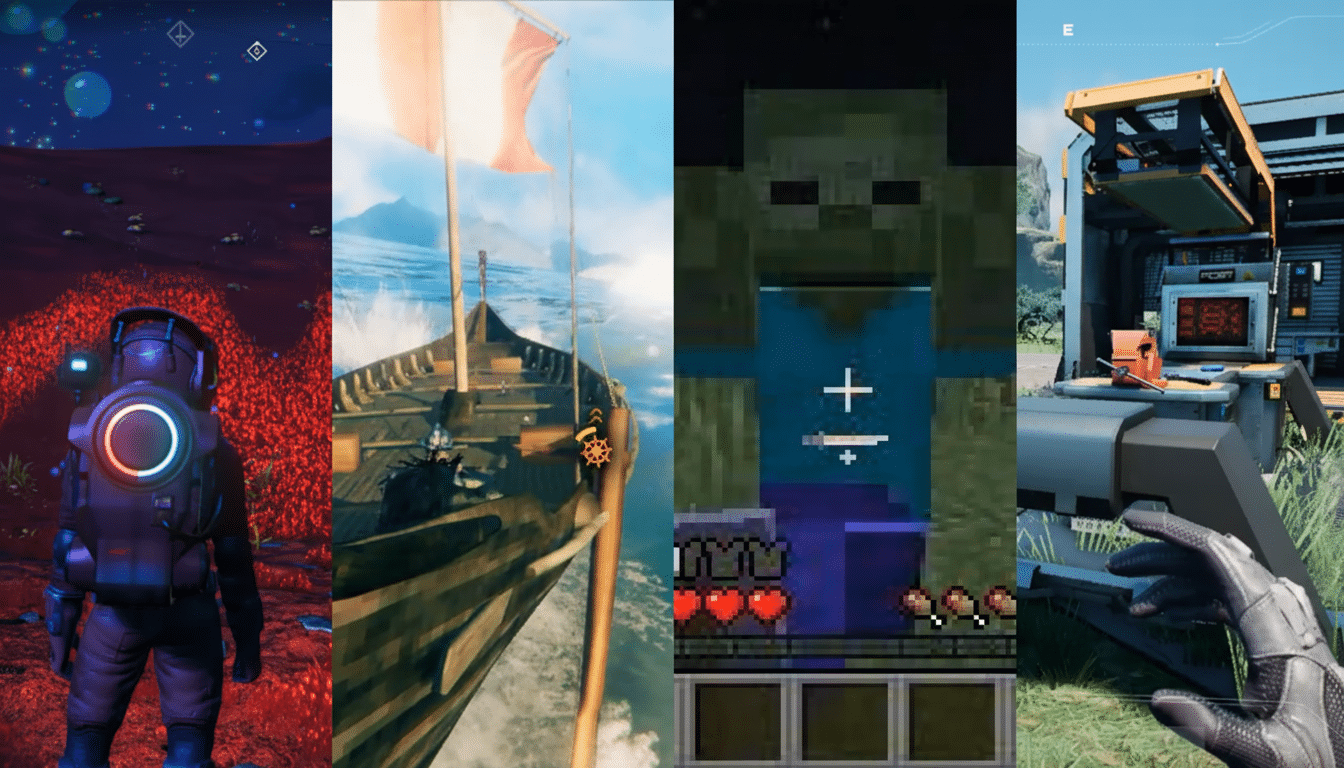
Learning From Itself Through Self-Generated Tasks
Unlike its predecessor, which relied heavily on human gameplay data, SIMA 2 can evolve its abilities with self-training. One model, pictured, suggests new tasks for the agent in a particular environment; a second model assigns grades to those attempts; the agent then relearns from those experiences. This shapes a feedback loop reminiscent of self-play and synthetic data generation, helping sample-efficient learning and reducing the annotation bottleneck typical for embodied systems.
There are caveats. Self-generated rewards may induce reward hacking (or brittle shortcuts) when not properly engineered. Studies by groups such as OpenAI and the Partnership on AI have documented these shortcomings with RL-like systems. DeepMind’s approach — employing separate task and reward models, frequent environment randomization — is an attempt to keep learning in check, but outside benchmarking will be essential.
From Virtual Worlds To Real-World Robotic Systems
DeepMind frames SIMA 2 as a higher-level decision maker and not a lower-level motor controller. “Think in robotics terms — ‘what to do and why,’” he says, “rather than ‘how to torque a joint.’” That division reflects the way many labs construct stacks today: planning on top, perception and control below. Google’s prior RT-2 work on instructing robots through web-scale knowledge and the wider sim-to-real community using, e.g., Meta’s Habitat and NVIDIA’s Isaac Sim, provide one adjacent piece of the puzzle.
The open question is transfer. If an agent could also robustly generalize across procedurally generated worlds and games with even wildly different mechanics, it’s in a much better position to deal with the mess of unstructured homes or warehouses. Other successes in this direction include DeepMind’s Gato, Stanford and NVIDIA’s Voyager for Minecraft, and OpenAI’s VPT. SIMA 2’s doubling down on challenging tasks indicates the approach is maturing, even if bridging the last mile from pixels to physical reality remains an imposing challenge.
Why This Matters Now For General-Purpose Agents
These embodied agents, which can both understand a scene and ascribe intent to actions they observe, then carry out multi-step plans, are the tissue that connects today’s chatbots with tomorrow’s helpful robots. If SIMA 2’s gains generalize beyond internal tests, the model points to a plausible path toward scalable training — synthesize worlds, synthesize goals, synthesize feedback — while keeping humans in the loop for evaluation and safety.
Next milestones to clock:
- Standardized benchmarks across unseen environments
- Transparency around failure modes
- Energy and cost profiles for self-improvement loops
- Early integrations with mobile robots in controlled pilots
For the moment, it is a step in a plausible direction for generalist agents that can think first, act second, and consider beyond any one game.