OpenAI is launching an easier, quicker way to chat with ChatGPT: Voice Mode, now hosted right inside your chats. Rather than being taken to a dedicated voice screen, you can tap the mic in the composer, speak as you normally would, and see live transcription appear line by line while answers pop up, complete with rich context cards—maps, weather, and other at-a-glance visuals—all without leaving the thread.
What’s Different With In-Chat Voice and Why It Feels More Natural
The transformation reduces this to a single interface. Before, Voice Mode would boot up a whole screen view with the orb pulsing. Now, all of the voice interactions are part and parcel with your text conversations. You can talk, watch the transcript polish itself in real time, and scroll back to earlier moments in the conversation as you would a normal chat. Responses can mix spoken answers with on-screen components like a map tile for directions or a small weather forecast card if you’re asking about the conditions outside.
- What’s Different With In-Chat Voice and Why It Feels More Natural
- How Voice Works on Web and Mobile, With a New Toggle
- Advanced Voice for Paid Users: Faster, More Expressive
- Why This Matters for Everyday Use on Phones and Wearables
- Privacy and Controls: Data, Admin Policies, and Options
- Real-World Use Cases from Cooking to Commuting and Study
- Where It Fits in the AI Race: Multimodal, Real-Time Assistants
That’s pretty close to what the best real-time helpers aim for—no mode switching. It jibes with how users already message their friends: tap, talk, and keep everything in one scrollable history. Live transcripts smooth over rapid corrections and accessibility issues—the “what did it just say?” problem of pure audio assistants.
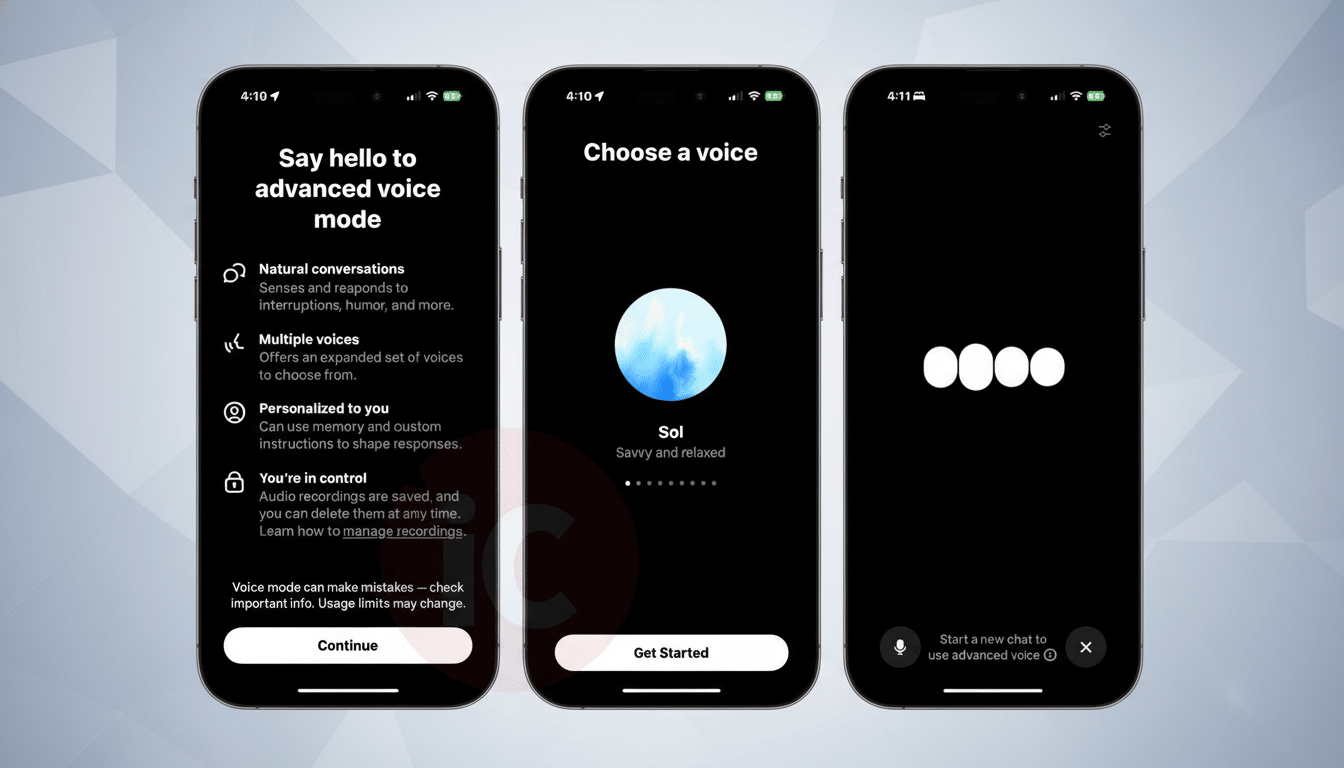
How Voice Works on Web and Mobile, With a New Toggle
On the mobile app and web, a microphone icon in the chat composer initiates Voice Mode. Just speak as you would; things like pauses, intonation, and overlapping ideas can be understood by ChatGPT, and it then generates a response that is concurrently being read back while populating the text transcript. If you prefer the old, full-screen experience, however, there’s a “Separate mode” toggle under Settings > Voice Mode to bring back focused access to the voice UI.
That translates to asking for a coffee walk route, getting a preview of the route right underneath that message, and then following up with your voice without disrupting the flow. The same applies to quick checks—“Do I need an umbrella?”—where an inline card will reply quicker than a paragraph of text.
Advanced Voice for Paid Users: Faster, More Expressive
OpenAI also offers two modes, a regular Voice Mode for all users and Advanced Voice Mode on its paid plans. Building on what was first demonstrated with GPT-4o, the real-time capabilities of Advanced Voice feature faster turn-taking combined with more expressive, low-latency speech. The in-chat upgrade doesn’t affect who receives which models, but it adds urgency to the two tiers by eliminating interface friction.
If you’re already on a paid plan, expect snappier back-and-forth and more naturally placed interruptions—like talking with a person. Free users still get the combined view and live transcript, which firewalls off enough bad hearsay prompts—as well as questions you’ve already fielded a half-dozen times before lunch—to be worth mentioning here.
Why This Matters for Everyday Use on Phones and Wearables
Voice is quietly emerging as a dominant input for everyday computing, especially on phones and wearables. The mainstream adoption of voice assistants has been gradual, as shown by Edison Research, which continues to report steady growth in usage, and the enterprise-scope surveys from Gartner indicate conversational interfaces manage an increasing percentage of customer interactions. By integrating Voice Mode in the main chat, OpenAI is inching ChatGPT closer to the always-on assistant that people desire, but through a medium that still respects text and visuals as useful tools.
It also tightens the competitive squeeze with products such as Google’s Gemini Live, which focuses on fluid, real-time conversation, as well as the incumbents in ambient voice most of all—Alexa and Siri. The catch here is that you’ll have a thread of conversation—but instead of just existing in audio, your voice conversation will turn into a transcribed chat history that can be searched and shared with context cards you can return to.
Privacy and Controls: Data, Admin Policies, and Options
As in text chats, audio cues and transcripts are sent through OpenAI for responses to be generated. Users can also control data collection in settings, and enterprise and education customers have administrative policies that limit training on their data. The live transcript makes the interaction more transparent, revealing exactly what the model heard, which helps catch misrecognitions before they are on the record.
If you’re sharing a device or working with ChatGPT in a professional context, there are advantages for cleaning up sensitive topics, too: you can remove individual turns or clear out an entire thread without combing through voice history elsewhere.
Real-World Use Cases from Cooking to Commuting and Study
Cooking with messy hands would be easier: say your substitutions and see a one-liner of instruction on the screen, then have it read back—even while continuing to chop.
Commuters can request the best route, then tap their way through a compact map preview before hitting the road.
For language practice, students can try a language out loud and receive transcript feedback with the correct spelling and accent.
For knowledge workers, the capacity to voice-dictate quick notes and ask follow-on questions by voice while containing the entire interaction in one thread minimizes context-switching. You can also begin by voice and end by typing, since the model is stateful between the two modalities.
Where It Fits in the AI Race: Multimodal, Real-Time Assistants
The shift is part of an industrywide swing toward multimodal assistants that can listen and respond via voice, text, and visuals. Stanford’s AI Index and several industry reports emphasize that real-time, low-latency models are now the new normal. In this way, by turning Voice Mode into the default for chats, OpenAI is offering a bet that conversation—not just prompts—will be the next UI, and that value can emerge through fusing speech with the structure and recall of a chat timeline.
It’s a small interface change that has outsized impact: fewer taps, clearer context, and no more having to navigate multiple spots for where you talk, read, and act. That can make the difference between occasional voice use and using it all day for both casual users and power users.