The cloud platform of Amazon Web Services was said to be running normally again after a widespread disruption related to problems with DNS resolution. Amazon has pledged to release a post-incident summary, with customers watching it closely for an accurate root cause and remediation plan plus advice on prevention of a recurrence.
The scale was hard to ignore: Outage-tracking firm Downdetector reported more than 9.8 million total problem reports worldwide at peak, roughly 2,000 companies listed issues, and hundreds hung around even as service started improving. The results were ripple effects felt across finance, streaming, gaming, communications, and smart home services built on AWS infrastructure.
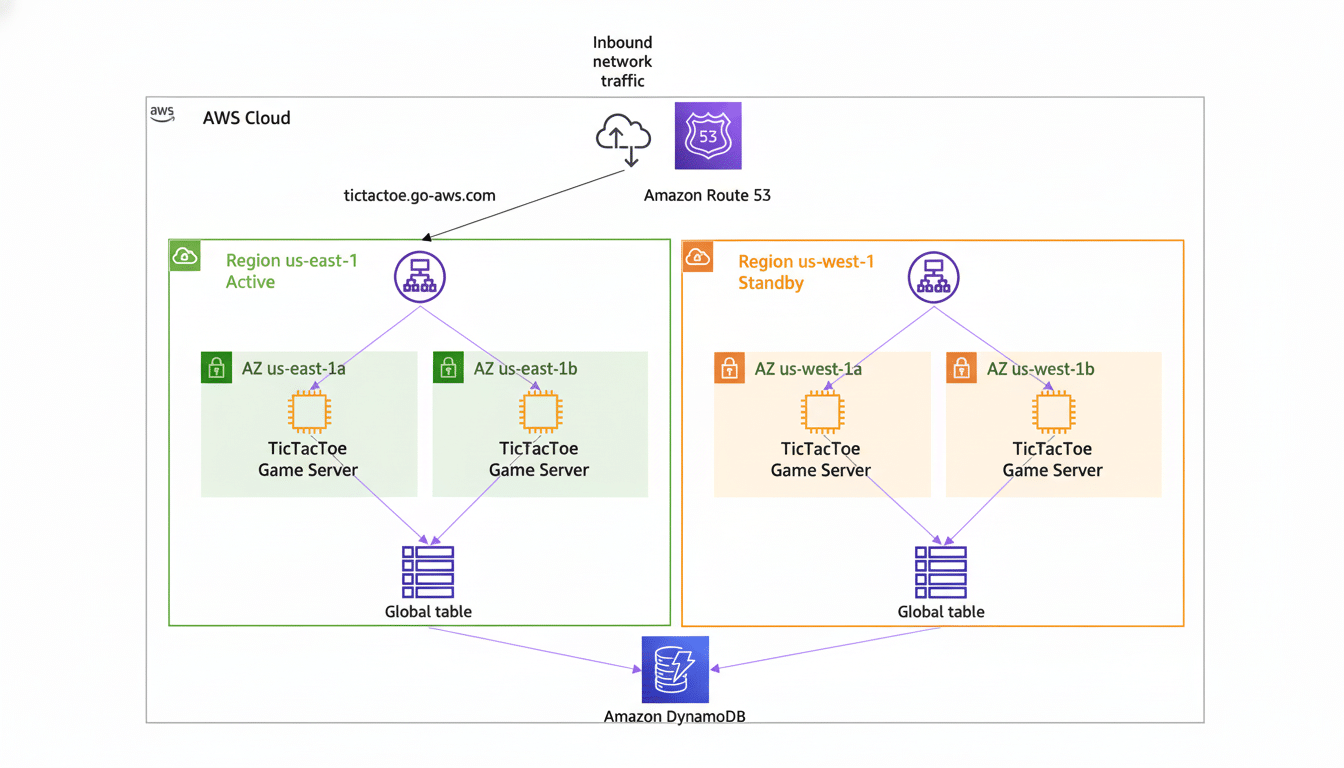
What we know so far about AWS’s DNS-related outage recovery
The cause according to Amazon was DNS resolution problems. DNS is the address book of the internet, and inside a modern cloud estate it’s also the nervous system for service discovery. When resolvers fail, microservices can’t locate each other; authentication endpoints don’t resolve; clients stare at timeouts instead of clean errors. The result is a ripple effect of cascading: retries flood in, queues back up, and even health components can be brought to their knees due to dependency timeouts.
As the mitigations were being rolled out, AWS was reporting “strong indications of recovery” as it fought through a backlog of queued requests—exactly what to expect when resolvers stabilize and caches repopulate.
The next AWS summary should call out customer-facing Route 53 behavior vs. the internal AmazonProvidedDNS for workloads inside VPCs, and control-plane impacts.
Scope and impact across services during the AWS outage
High-profile consumer brands reported trouble, including streaming platforms, social and communications apps, and companies in the fintech space.
Gaming services and games were affected as well, with login and matchmaking issues. A number of Amazon’s own products and services, including Alexa, Prime Video, Ring, Blink systems, and Amazon Music, were also affected by the outage on Thursday morning—underscoring just how crucial DNS can be to the flow of internal as well as customer traffic.
In addition to visible outages, performance-monitoring companies like ThousandEyes and Cloudflare Radar have seen increased error rates and latency spikes to AWS endpoints during other incidents when DNS was unstable.
Though each such provider has their own view of the issue, the behavior is common: even small amounts of DNS flapping explode across API calls, CDNs, and mobile clients.
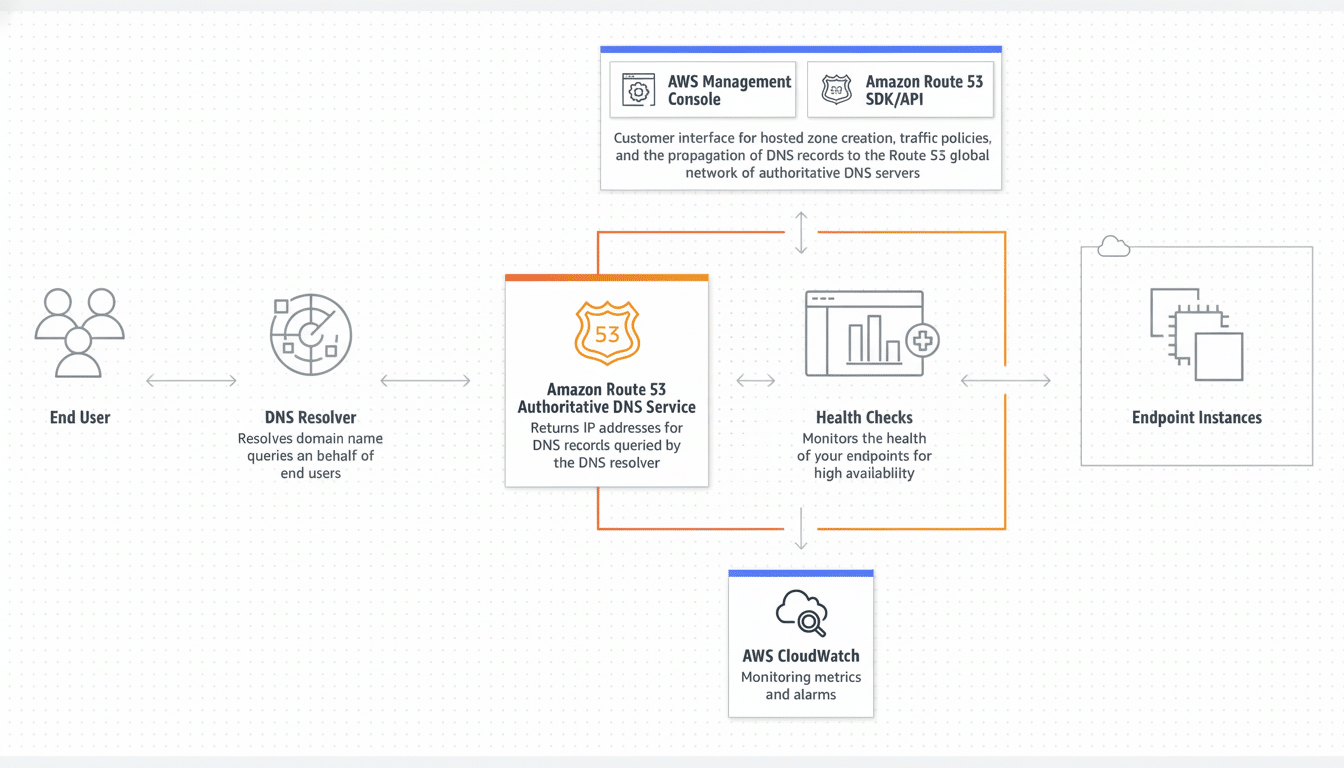
The economic stakes are significant. Analysis by industry bodies Uptime Institute and Gartner has for some time suggested that downtime at scale has the potential to cost tens of millions of dollars per hour across multiple affected sectors. With AWS accounting for nearly a third of all cloud infrastructure revenue around the world, according to Synergy Research, a widespread DNS failure hits an uncharacteristically large swath of the internet economy.
Amazon’s response and what to expect in the postmortem
According to AWS, services are now fully operational and the company plans to provide a detailed summary of what caused the service interruption as soon as possible. These reports through the years typically take the format of an incident timeline, technical root cause, contributing factors, and long-term fixes. For DNS-specific events, this can cover enhanced protections around recursive resolvers, tighter geographic isolation, and better negative caching behavior, as well as measures to prevent retry storms from augmenting the blast radius.
Key questions that customers will be interested in having answers to:
- Were problems limited to specific geographies or widely distributed?
- Was the impact primarily on Route 53’s authoritative services, private hosted zones, or AmazonProvidedDNS resolvers?
- What impact did client-side caching, TTLs, and backoff policies have on recovery?
Clear answers here will inform practical hardening moves for architects.
Lessons for cloud architects to improve DNS resilience
Resilience starts with architecture. Spread essential applications across different availability zones and, if possible, different regions. Leverage Route 53 health checks and failover policies to direct traffic away from unhealthy endpoints. For internal DNS resolution, conditional forwarding and using two resolvers can help eliminate a choke point.
Use exponential backoff on the application layer, circuit breakers, and aggressive caching for configuration or service discovery. Verify that identity and telemetry paths have fallbacks. Organizations developing SRE practices should also run regular game days to experiment with DNS failure modes and observe saturation on queues and thread pools during an incident drill.
Multi-cloud plays. Some organizations may be reconsidering multi-cloud strategies in the context of concentration risk. Yes, multi-cloud introduces complexity, but localized redundancy for customer-facing authentication, payments, or content delivery can minimize risk. Regulatory and policy focus on hyperscaler concentration will also probably increase every time a failure of a fundamental service brings down large parts of the internet.
The bottom line for AWS customers after the DNS outage
AWS has restored services and promised to fully account for what went wrong. The upcoming postmortem will bring clarity to the specifics of how the DNS resolution issue unfurled, cascaded, and what kind of lasting fixes are being rolled out. For customers, the key takeaway is straightforward: assume core dependencies are able to fail, model explicit controls for DNS lability, and continue practicing their recoveries until the next real-world situation comes into play.