Anthropic has rolled out Sonnet 4.6, the newest iteration of its mid-size Claude family model, highlighting upgrades in coding reliability, instruction-following, and computer use. The company is making Sonnet 4.6 the default for Free and Pro plan users, signaling confidence that this update is stable and broadly capable rather than just a research preview.
Arriving shortly after the flagship Opus 4.6, the new Sonnet debuts with a beta context window of 1 million tokens—twice the largest previously available on Sonnet. That scale changes practical workflows, enabling single-shot queries that can encompass an entire codebase, a complex contract portfolio, or a stack of long-form research papers without elaborate chunking strategies.
What’s New in Sonnet 4.6: coding reliability and computer use
Anthropic says Sonnet 4.6 is better at following granular instructions and executing multi-step procedures on a computer, the kind of “do this, then that” work that often breaks weaker agents. On the coding front, the company points to improved success rates on software engineering tasks and fewer off-by-one and edge-case errors—pain points that developers often flag when models interact with large codebases.
The headliner is the 1M-token context window. In practical terms, that’s on the order of hundreds of thousands of words—enough for entire repositories, long compliance documents, or comprehensive technical specs to fit in a single request. For product teams, it reduces the need for brittle retrieval pipelines or aggressive summarization that can strip away nuance.
By making Sonnet 4.6 the default model for Free and Pro users, Anthropic is placing these gains into the hands of the broadest slice of its customer base. That move should surface real-world signal quickly: expect feedback from engineers running repository-wide refactors, analysts comparing procurement agreements, and researchers synthesizing literature sets that previously exceeded context limits.
Benchmarks and how to read them: OSWorld, SWE-Bench, ARC-AGI-2
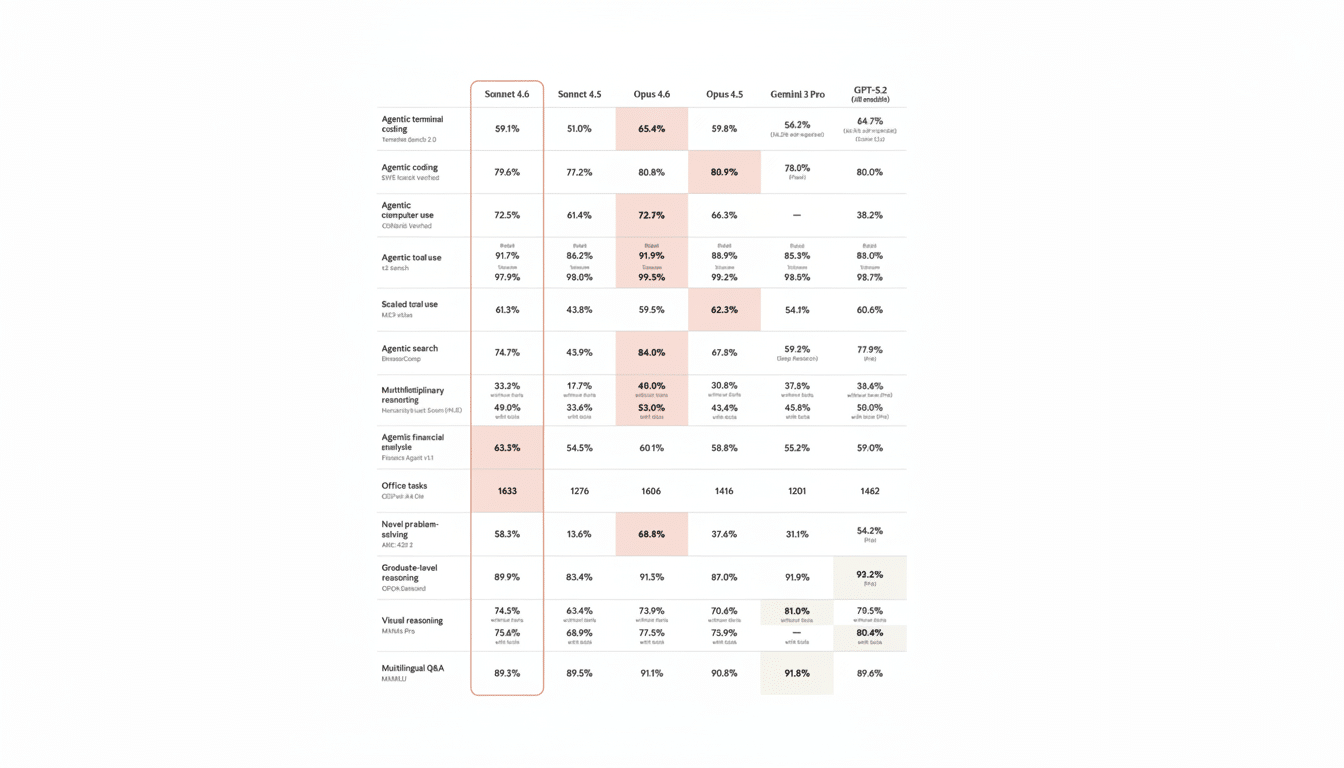
Sonnet 4.6 arrives with record internal scores on widely watched evaluations: OSWorld for computer-use tasks and SWE-Bench for software engineering. Perhaps most notable is a 60.4% result on ARC-AGI-2, a challenging successor in the ARC family of tests devised by Google researcher François Chollet to probe abstract reasoning and generalization rather than memorized knowledge.
Context matters: Anthropic positions Sonnet 4.6 ahead of most comparable mid-size models on these runs, while acknowledging it still trails top-tier systems like Opus 4.6, Google’s Gemini 3 Deep Think, and a refined build of GPT 5.2 on certain leaderboards. As always, cross-benchmark comparisons can be noisy—prompting, tool access, and evaluation harnesses materially influence outcomes—so developers should pair headline scores with task-specific trials.
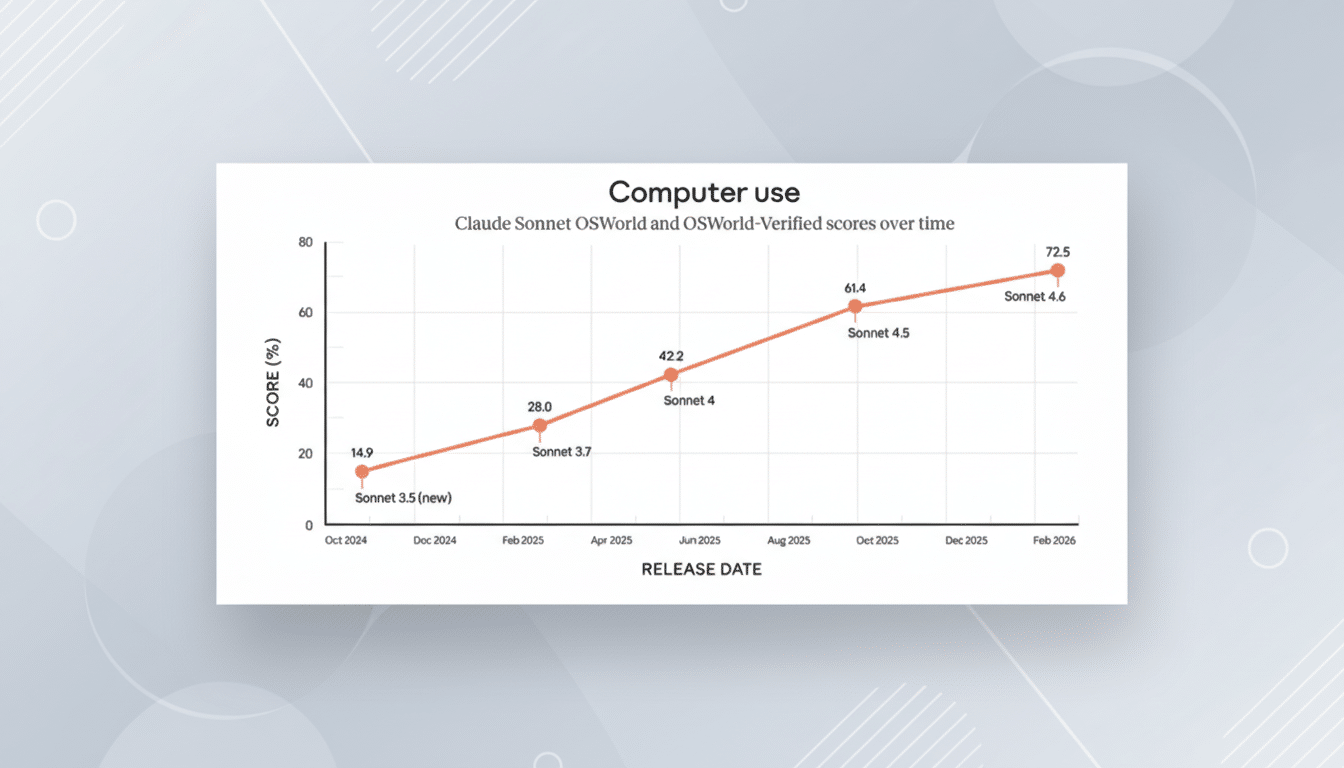
For grounding, SWE-Bench—originally introduced by Princeton researchers—assesses whether a model can read issues and tests from real open-source projects and generate patches that pass. OSWorld measures step-by-step software handling in a desktop environment. Strong results there align with Anthropic’s emphasis on dependable computer use and instruction-following.
Why the 1M-token window matters for real-world workflows
Large context windows don’t just mean “more text.” They change what teams can attempt in one pass. Imagine asking the model to map a monorepo’s architectural dependencies, propose a migration plan, and draft the refactor sequence—without slicing the repo into dozens of separate calls. Legal teams can load a bundle of vendor agreements to reconcile indemnity clauses across versions. Scientists can ingest dozens of methods sections to spot confounding variables missed in summaries.
There are caveats. A bigger window increases the risk of burying the most relevant details, so prompt design and structured references still matter. But when paired with careful instructions—think signposted sections, explicit objectives, and verification steps—the expanded window can reduce information loss and improve end-to-end fidelity.
Position in Anthropic’s lineup: between Haiku and Opus models
Sonnet sits between the smaller, latency-focused Haiku and the heavyweight Opus. With Opus 4.6 already out and an updated Haiku expected, Anthropic is maintaining a steady cadence where the flagship sets the upper bound and Sonnet absorbs a large share of those capabilities at a more accessible footprint.
For many organizations, that balance is the sweet spot: strong reasoning and tool-use performance, now backed by a 1M-token context, without the compute profile of a top-end model. Making it the default for Free and Pro tiers also broadens the test surface, accelerating the feedback loop that typically drives rapid point releases.
What developers should try first with the new Sonnet 4.6
- End-to-end repo tasks: load project docs, tests, and core modules together; ask for a migration plan and sample diffs, then validate with your CI.
- Compliance and policy reviews at scale: insert the full text of related agreements and require side-by-side clause mapping with citations to source passages.
- Research synthesis: provide the methods and results sections from multiple papers and request contradictions, confounds, and follow-up experiments.
With Sonnet 4.6, Anthropic is not just inching up benchmark charts; it is expanding the size of the problems a mid-size model can credibly tackle in one go. For teams that have been bumping into context ceilings, this release invites a different kind of prompt—bigger, but also more deliberate.