Anthropic has rolled out Claude Sonnet 4.6, a mid-tier flagship tuned for long-context work, safer outputs, and stronger coding. The company is positioning Sonnet 4.6 as its most capable Sonnet yet, with a 1 million token context window in beta and upgraded tool use for day‑to‑day analysis and automation.
Early signals suggest this release is less about raw IQ points and more about practical throughput: fewer hallucinations and less sycophancy, better adherence to instructions, and faster iteration on office and engineering tasks. That mix has already led some developers to prefer Sonnet 4.6 over more expensive tiers for routine workflows.
What’s New in Claude Sonnet 4.6: Context and Tool Upgrades
The headline upgrade is the 1M-token context window (beta), enabling multi-hundred-page document reviews, large codebase navigation, and dense meeting or research digestion without aggressive chunking. That capability matters for retrieval-augmented generation setups that previously hit context ceilings.
Anthropic also highlights internal safety evaluations showing reduced hallucination rates and lower sycophancy, a known failure mode where models mirror user assumptions. Those shifts track with broader emphasis in model alignment research from organizations like Anthropic’s own Safety team and initiatives aligned with NIST’s AI Risk Management Framework.
For developers, Sonnet 4.6 brings steadier code synthesis and debugging, improved tool invocation, and better function planning. In practice, that shows up as cleaner diffs, more accurate dependency handling, and fewer speculative edits when the model is uncertain.
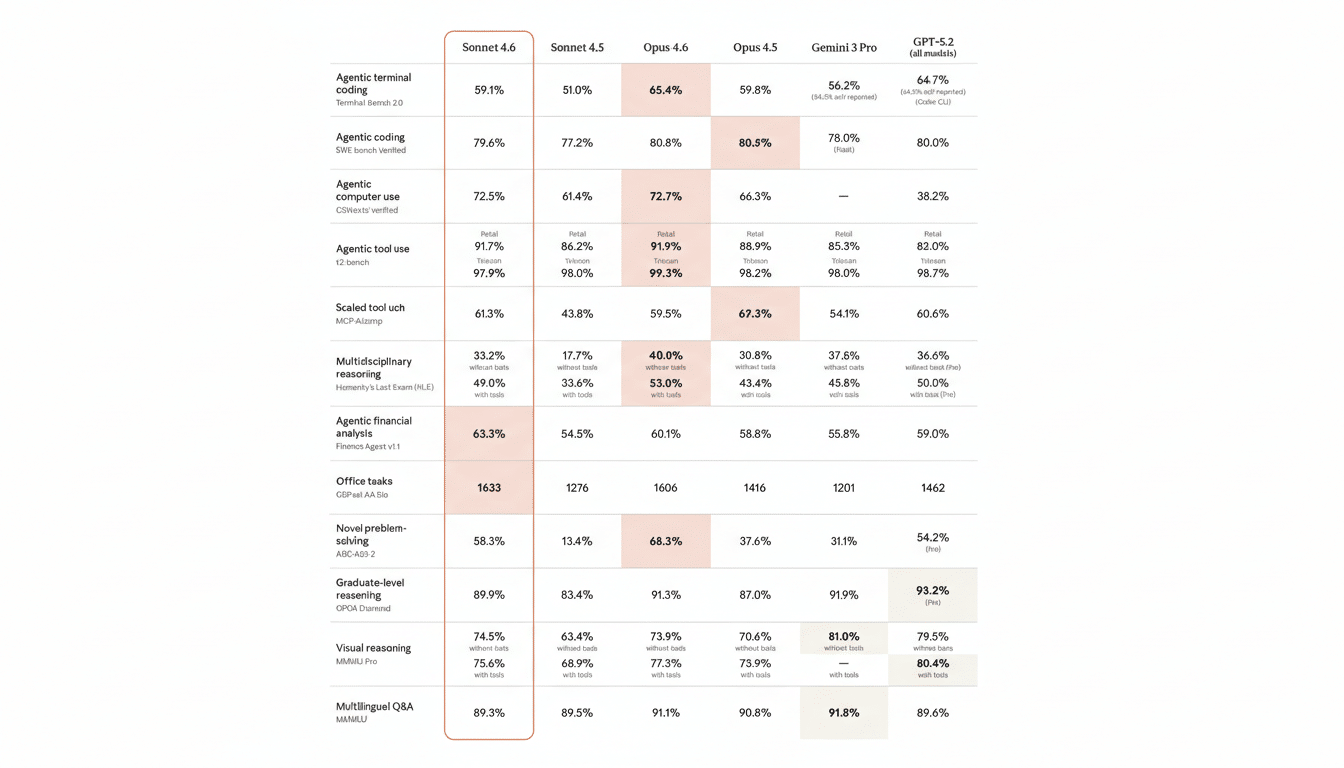
Benchmark Results and Competitors for Claude Sonnet 4.6
According to Anthropic’s system card, Sonnet 4.6 posts competitive scores across popular evaluations: GPQA Diamond at 89.9%, ARC-AGI‑2 at 58.3%, MMLU at 89.3%, and SWE‑bench Verified at 79.6%. On Humanity’s Last Exam, it records 49.0% with tools and 33.2% without tools. While top-line scores are not a perfect proxy for real-world performance, these figures indicate a strong generalist with particular gains in tool-augmented reasoning.
Anthropic reports that in agentic financial analysis and office workloads, Sonnet 4.6 outperformed Google’s Gemini 3 Pro and OpenAI’s GPT 5.2 in internal tests. Notably, it also surpassed Anthropic’s own Opus 4.6 on these task categories, despite Opus models typically leading on complex reasoning. Third-party feedback echoes this pattern: AI-powered insurer Pace told VentureBeat that Sonnet 4.6 topped previous Claude models on its complex insurance computer-use benchmark.
The picture that emerges is pragmatic: Opus remains a go-to for peak reasoning on some academic-style tasks, but Sonnet 4.6 appears to deliver better price-performance for structured, tool-heavy workflows common in finance, research ops, customer support, and engineering assistance.
How to Try Claude Sonnet 4.6 on the Web and via API
On the web, Sonnet 4.6 is the default model for both free and Pro tiers in the Claude app and Claude Cowork. Sign in and start a new chat to use it immediately; no manual model switch is required for most users.
Through the API, Sonnet 4.6 is available now under the standard Sonnet endpoint. Anthropic says it is also live across major cloud providers; if your team provisions models via managed services, check your organization’s console for the latest Sonnet option and region availability.
Free accounts have rolling usage limits that reset approximately every five hours, making it easy to trial longer-context prompts without immediate cost. Teams evaluating automation or RAG scenarios can prototype in the app, then shift to the API for higher throughput and monitoring.
Pricing and Rate Limits for Claude Sonnet 4.6 Access
Anthropic keeps Sonnet pricing aggressive: $3 per million input tokens and $15 per million output tokens via the API. That undercuts Opus 4.6, which lists at $5 per million input and $25 per million output, and tilts the calculus toward Sonnet for iterative or high-volume tasks.
For individuals, Claude Pro remains $20 per month, or $17 per month with annual billing, adding higher limits and faster access during peak demand. Organizations should model prompt budgets around expected output length; for long-context analysis, the output side often dominates costs.
Why This Claude Sonnet 4.6 Release Matters for Teams
Sonnet 4.6 is a signal of where mid-tier models are heading: bigger context, tighter safety, and stronger tool chains that close much of the gap with top-end systems at a fraction of the cost. For many companies, that combination will justify standardizing on Sonnet for everyday automation while reserving premium models for edge cases that truly need maximal reasoning headroom.
If your roadmap includes multi-document reviews, financial reconciliations, or codebase navigation that once felt brittle, Sonnet 4.6 is a timely retest. The metric gains are real, but the practical win is steadier performance under real workload constraints—exactly where most AI deployments succeed or stumble.